HashMap与HashTable是用来存放键值对的一种容器,在使用这两个容器时有一个限制:不能用来存储重复的键。也就是说,每个键只能唯一映射一个值,当有重复的键时,不会创建新的映射关系,而会使用先前的键值。为了更好地说明这个问题,我们首先来看一段示例代码:
import Java.util.*;
public class Test{
public static void test1(){
System.out.println("Use user defined class as key:");
HashMap<String, String>hm=new HashMap<String, String>();
hm.put("aaa", "bbb");
hm.put("aaa", "ccc");
Iterator iter=hm.entrySet().iterator();
while(iter.hasNext()){
Map.Entry entry=(Map.Entry)iter.next();
String key=(String)entry.getKey();
String val=(String)entry.getValue();
System.out.println(key+" "+val);
}
}
public static void main(String args[]){
test1();
}
}
程序运行结果为:
Use user defined class as key:
aaa ccc
从上面的例子可以看出,首先向HashMap中添加<"aaa", "bbb">,接着添加<"aaa", "ccc">的时候由于与前面已经添加的数据有相同的key:"aaa",因此会用新的值"ccc"替换"bbb"。
但当用自定义的类的对象作为HashMap的key时,有时候会给人造成一种假象——key是可以重复的,示例如下:
import Java.util.*;
class Person{
String id;
String name;
public Person(String id, String name){
this.id=id;
this.name=name;
public String toString(){
return "id="+id+".name="+name;
}
}
public class Test{
public static void test2(){
System.out.println("Use String as key:");
HashMap<Person.String>hm=new HashMap<Person, String>();
Person p1=new Person("111", "name1");
Person p2=new Person("111", "name1");
hm.put(p1, "address1");
hm.put(p2, "address1");
Iterator iter=hm.entrySet().iterator();
while(iter.hasNext()){
Map.Entry entry=(Map.Entry)iter.next();
Person key=(Person)entry.getKey();
String val=(String)entry.getValue();
System.out.printin("key=" +key+" value="+val);
}
}
public static void main(String args[]){
test2();
}
}
程序运行结果为:
Use String as key:
key=id=111, name=name1 value=address1
key=id=111, name=name1 value=address1
从表面上看,向HashMap中添加的两个键值对的key值是相同的,可是为什么在后面添加的键值对没有覆盖前面的value呢?为了说明这个问题,下面首先介绍HashMap添加元素的操作过程。具体而言,在向HashMap中添加键值对<key,value>时,需要经过如下几个步骤:首先,调用key的hashCode()方法生成一个hash值h1,如果这个h1在HashMap中不存在,那么直接将<key,value>添加到HashMap中;如果这个h1已经存在,那么找出HashMap中所有hash值为h1的key,然后分别调用key的equals()方法判断当前添加的key值是否与已经存在的key值相同。如果equals()方法返回true,说明当前需要添加的key已经存在,那么HashMap会使用新的value值来覆盖掉旧的value值;如果equals()方法返回false,说明新增加的key在HashMap中不存在,因此会在HashMap中创建新的映射关系。当新增加的key的hash值已经在HashMap中存在时,就会产生冲突。一般而言,对于不同的key值可能会得到相同的hash值,因此就需要对冲突进行处理。一般而言,处理冲突的方法有开放地址法、再hash法、链地址法等。HashMap使用的是链地址法来解决冲突,具体操作方法如图所示。
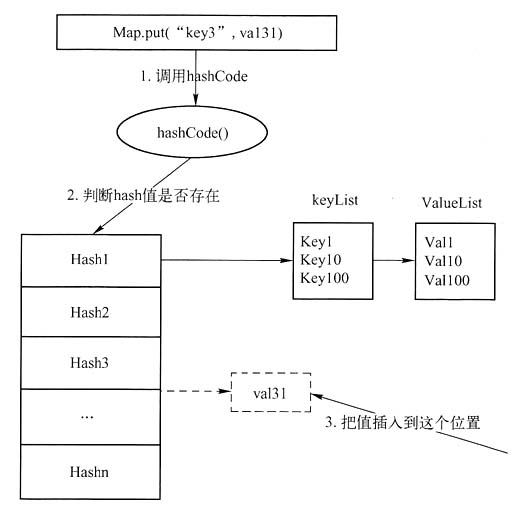
May工作原理1
向HashMap中添加元素时,若有冲突产生,其实现方式如图所示。
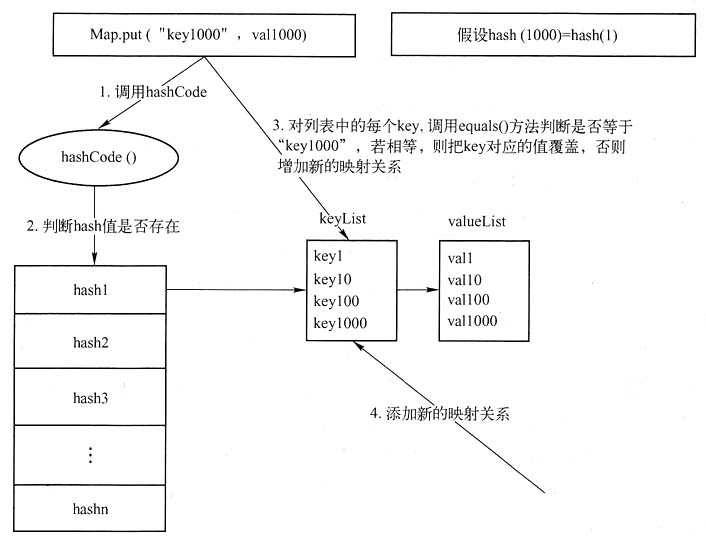
Map工作原理2
从HashMap中通过key查找value时,首先调用的是key的hashCode()方法来获取到key对应的hash值h,这样就可以确定键为key的所有值存储的首地址。如果h对应的key值有多个,那么程序接着会遍历所有key,通过调用key的equals()方法来判断key的内容是否相等。只有当equals()方法的返回值为true时,对应的value才是正确的结果。
在上例中,由于使用自定义的类作为HashMap的key,而没有重写hashCode()方法和equals()方法,默认使用的是Object类的hashCode()方法和equals()方法。Object类的equals()方法的比较规则如下:当参数obj引用的对象与当前对象为同一个对象时,就返回true,否则返回false。hashCode()方法会返回对象存储的内存地址。由于在上例中创建了两个对象,虽然它们拥有相同的内容,但是存储在内存中不同的地址,因此在向HashMap中添加对象时,调用equals()方法的返回值为false,HashMap会认为它们是两个不同的对象,就会分别创建不同的映射关系,因此为了实现在向HashMap中添加键值对,可以根据对象的内容来判断两个对象是否相等,这就需要重写hashCode()方法和equals()方法,示例如下:
import Java.util.*;
class Person{
String id;
String name;
public int hashCode(){
return id.hashCode();
}
public Person(String id, String name){
this.id=id;
this.name=name;
}
public String toString(){
return "id="+id+", name="+name;
}
public boolean equals(Object obj){
Person p=(Person)obj;
if(p.id.equals(this.id))
return true;
else
return false;
}
}
public class Test{
public static void test2(){
System.out.println("Use String as key:");
HashMap<Person, String>hm=new HashMap<Person, String>();
Person p1=new Person("111", "name1");
Person p2=new Person("111", "name2");
hm.put(p1, "address1");
hm.put(p2, "address2");
Iterator iter=hm.entrySet().iterator();
while(iter.hasNext()){
Map.Entry entry=(Map.Entry)iter.next();
Person key=(Person)entry.getKey();
String val=(String)entry.getValue();
System.out.println("key="+key+" value="+val);
}
}
public static void main(String args[]){
test2();
}
}
程序运行结果为:
Use String as key:
key=id=111, name=name1 value=address2
由此可以看出,开发者在使用白定义类作为HashMap的key时,需要注意以下几个问题:
1)如果想根据对象的相关属性来自定义对象是否相等的逻辑,此时就需要重写equals()方法,一旦重写了equals()方法,那么就必须重写hashCode()方法。
2)当自定义类的多项作为HashMap(HashTable)的key时,最好把这个类设计为不可变类。
3)从HashMap的工作原理可以看出,如果两个对象相等,那么这两个对象有着相同的hashCode,反之则不成立。




 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题