一、单选题 14. 在SQL Server 2008中,要为数据库DB1添加一个新的数据文件,该文件的逻辑名为data2,物理存储位置为D:\Data\data2.ndf,初始大小为10MB,每次自动增长20%。下列语句中正确的是______。
A.ALTER DATABASE DB1 ADD FILE ( B.ALTER DATABASE DB1 ADD FILE ( C.ALTER DATABASE DB1 ADD FILE ( D.ALTER DATABASE DB1 ADD FILE (
A
[解析] 添加数据库文件的语法格式是:
15. 设在SQL Server 2008中,用户U1是某数据库中db_datawriter角色中的成员。有下列针对该数据库的操作语句
Ⅰ.SELECT * FROM T
Ⅱ.DELETE FROM T
Ⅲ.UPDATE T SET C1 = 100
Ⅳ.INSERT INTO T VALUES...
上述语句中,U1有权执行的是______。
C
[解析] db_datawriter角色具有插入、删除和更改数据库中所有用户数据的权限,不具备查询的权限。故答案为C项。
二、应用题 1. 没有商品表(商品号,商品名,商品类别),其中商品号为主码,商品名和商品类别不为空。现要统计商品数量最多的前3类商品(包括并列情况),希望列出商品类别和商品数量。请补全下列语句:
SELECT______商品类别,COUNT(*)AS商品数量
FROM商品表
GROUP BY商品类别
ORDER BY COUNT(*)DESC
TOP 3 WITH TIES
[解析] 希望选出商品数量最多的前3类商品,并获得相应的商品类别和数量。with ties一般是和Top、order by相结合使用,表示包括与最后一行order by后面的参数取值并列的结果。
2. 在IDEFIX数据建模方法中,多对多联系又被称作非______联系。
确定
[解析] 在IDEFIX数据建模方法中,所有实体集间的联系都必须用确定联系来描述,不允许出现不确定联系,多对多联系为非确定联系,非确定联系需要分解为若干个一对多的联系。故答案为确定。
3. 在并行数据库中,______结构被认为是支持并行数据库系统的最好并行结构,适用于银行出纳之类的应用。
4. 在数据库系统出现系统故障后进行恢复时,对于事务T,如果在日志文件中有BEGIN TRANSACTION记录,也有COMMIT记录,但其对数据的修改没有写到数据库中,则数据库管理系统处理这种事务时应执行的操作是______。
5. 设某数据库中作者表(作者号、城市)和出版商表(出版商号,城市)。请补全如下查询语句,使该查询语句能查询出在作者表里而不在出版商表中的城市。
SELECT城市FROM作者表作者
______
(SELECT城市FROM出版商表)
WHERE作者.城市NOT IN
[解析] 要查询有作者但是没有出版社的结果集,可以采用子查询手段,即从作者表中查询城市,且城市不在出版社所在的城市。这时我们可以用NOT IN来实现,NOT IN的结果集是在外查询中存在,但是在内查询中不存在的记录。
6. 在一个SELECT语句中,GROUP BY子句的逻辑执行顺序在ORDER BY子句之______。
前
[解析] SELECT基本语法格式是:
7. 数据从操作型环境转移到数据仓库过程中所用到ETL工具通常需要完成的处理操作包括抽取、转换和______。
装载
[解析] ETL是实现数据集成的主要技术,即填充更新数据仓库的数据抽取、转换、装载的数据采集过程。
8. 在OLAP的实现方式中,以多维数组作为存储结构的被称作______OLAP。
M
[解析] MOLAP称为基于多维库的0LAP,这种OLAP的核心是多维数据库技术。MOLAP工具以多维数据库的形式将元数据、基础事实数据和导出数据存储在以多维数组为基本存储结构的多维数据库中。
9. 数据库管理系统提供了数据定义语言(DDL),用于定义各种数据库对象。数据定义语句经DDL编译器编译后,各种对象的描述信息存放在数据库的______中。
数据字典
[解析] 数据字典是对系统中各类数据描述的集合,是进行详细的数据收集和数据分析所获得的主要成果。数据字典在数据库设计中占有很重要的地位,通常包括数据项、数据结构、数据流、数据存储和处理过程5个部分。
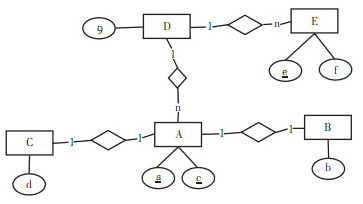
三、设计与应用题 1. 已知有如下关系模式:R1(a, b, c), R2(c, d, a), R3(e, f), R4(a, e, g),其中标下划线的属性是主码。请将上述关系模式用适当的ER图表示出来,并用下划线标注出作为实体主码的属性。
可以通过以下ER图来表示。a、c为A的候选码,可任选其一做主码。
[解析] ER模型和关系模式相互转换的一般规则如下:
(1)将每一个实体类型转换成一个关系模式,实体的属性为关系模式的属性。
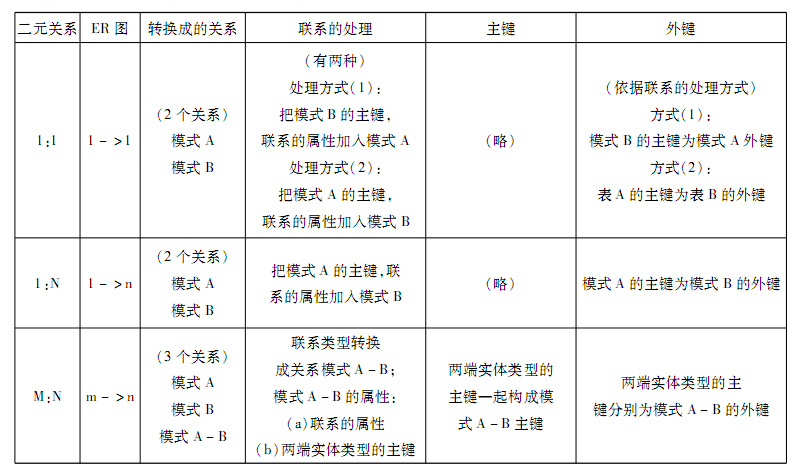
(2)对于二元联系,按各种情况处理,如下表格所示。
此题为关系模式转换为实体类型,因此采用实体→关系的逆向思维解题。从模式R1和R2可知,R1和R2为一对一关系,根据这两个模式的拆分可以确定三个实体,此处将这三个实体分别命名为A、B和C。其中A、B和C分别一一对应,且a和c分别是B和C的外键。从模式R1和R4可知,R1和R4为多对一关系,由此确定实体D。从模式R3和R4可知,R3和R4为多对一关系,由此可以确定出实体E。
2. 函数readDat()是从文件in.dat中读取20行数据存放到字符串数组xx中(每行字符串长度均小于80)。请编制函数jsSort(),其函数的功能是:以行为单位对字符串按下面给定的条件进行排序,排序后的结果仍按行重新存入字符串数组xx中,最后调用函数writeDat()把结果xx输出到文件out.dat中。
条件:字符串从中间一分为二,左边部分按字符的ASCII值降序排序,右边部分按字符的ASCII值升序排序。如果原字符串长度为奇数,则最中间的字符不参加排序,字符仍放在原位置上。
例如:位置 0 1 2 3 4 5 6 7 8
源字符串 a b c d h g f e
1 2 3 4 9 8 7 6 5
则处理后字符串 d c b a e f g h
4 3 2 1 9 5 6 7 8
请勿改动数据文件in.dat中的任何数据、主函数main()、读函数readDat()和写函数writeDat()的内容。
#include <stdio.h>
#include <string.h>
void readDat();
void writeDat();
char xx[20] [80];
void jsSort()
{
}
void main()
{
readDat ();
jsSort ();
writeDat ();
}
/*从文件in.dat中读取20行数据存放到字符串数组xx中*/
void readDat()
{
FILE *in;
int i=0;
char *p;
in=fopen("in.dat", "r");
while(i<20 && fgets(xx[i], 80, in) != NULL)
{
p=strchr(xx[i], '\n');
if(p) *p=0;
i++;
}
fclose(in);
}
/*把结果xx输出到文件out.dat中*/
void writeDat()
{
FILE *out;
int i;
out=fopen("out.dat", "w");
for(i=0; i<20; i++)
{
printf("%skn", xx[i]);
fprintf(out, "%s\n", xx[i]);
}
fclose (out);
}
char ch;
[解析] 以行为单位从字符串左边部分降序排序,右边部分升序排序。如果原字符串长度为奇数,则最中间的字符不参加处理。



 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题