银符考试题库B12
现在是:
试卷总分:100.0
您的得分:
考试时间为:
点击“开始答卷”进行答题





| SGA组件 | 初始化参数 | 是否会被ASMM自动调节 | ||||||||||||||||||||||||||||||||||||||||||||||||
| 共享池(Shared Pool) | SHARED_POOL_SIZE | Y | ||||||||||||||||||||||||||||||||||||||||||||||||
| 大池(Large Pool) | LARGE_POOL_SIZE | |||||||||||||||||||||||||||||||||||||||||||||||||
| Java池(Java Pool) | JAVA_POOL_SIZE | |||||||||||||||||||||||||||||||||||||||||||||||||
| 数据库缓冲区(Database Buffer Cache) | DB_CACHE_SIZE | |||||||||||||||||||||||||||||||||||||||||||||||||
| 流池(Streams Pool,10gR2新增) | STREAMS_POOL_SIZE | |||||||||||||||||||||||||||||||||||||||||||||||||
| Fixed SGA和其他Oracle数据库实例所需要的内存 | N/A | N | ||||||||||||||||||||||||||||||||||||||||||||||||
| 其他的数据库Buffer Cache | DB_nK_CACHE_SIZE,DB_ KEEP_CACHE_SIZE,DB_ RECYCLE_CACHE_SIZE |
|||||||||||||||||||||||||||||||||||||||||||||||||
| Redo日志缓冲区(Redo Log Buffer) | LOG_BUFFER | |||||||||||||||||||||||||||||||||||||||||||||||||
| 结果缓存(Result Cache) | RESULT_CACHE_SIZE | |||||||||||||||||||||||||||||||||||||||||||||||||


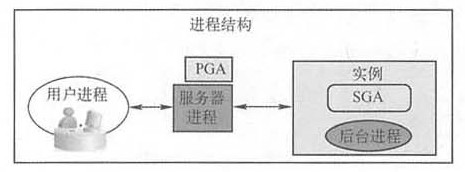

| 进 程 | 表现形式 | 描述 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SMON(System Monitor Process, 系统监控进程) |
ora_smon_ora11g | SMON进程关注的是系统级的操作而非单个进程,主要用于清除失效的用户进程,释放用 户进程所用的资源。具体有如下的功能: 1)清理临时表空间 2)合并空闲空间 3)从不可用的文件中恢复事务的活动 4)实例恢复(包括单实例和RAC) 5)清除SYS.OBJ$表 6)缩减回滚段 7)使回滚段脱机 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PMON(Process Monitoi Process, 进程监视进程) |
ora_pmon_ora11g | PMON进程主要有以下3个作用: 1)在其他进程失败后执行清除工作:回滚事务、释放锁、释放其他资源。若RECO进程异 常,则PMON重启RECO进程。若LGWR进程失败,则PMON会中止实例,防止数据错乱 2)注册数据库 3)检测会话的空闲连接时间 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| CKPT(Checkpoint Process,检查点 进程) |
ora_ckpt_ora11g | 检查点(Checkpoint)是一种将内存中的已修改数据块与磁盘上的数据文件进行同步的数 据库事件。Oracle通过检查点确保被事务修改过的数据可以被同步至磁盘。由于Oracle事务 在提交的时候不会将已修改数据块同步写入磁盘上,所以,CKPT进程负责更新控制文件和 数据文件的文件头的检查点信息和触发DBWn写脏数据到磁盘。CKPT执行越频繁,DBWn 写出就越频繁。检查点包括完全检查点、部分检查点和增量检查点等。检查点有两个用途: ①确保数据一致性;②实现更快的数据库恢复 CKPT工作的主要条件如下: 1)在日志切换(ALTER SYSTEM SWITCH LOGFILE)的时候 2)数据库用IMMEDIATE、TRANSACTION、NORMAL,或选项SHUTDOWN数据库的时候 3)根据参数FAST_START_MTTR_TARGET的设置来确定。如果当内存中产生的Dirty Buffer所需的恢复时间(estimated_mttr)到达FAST_START_MTTR_TARGET的指定时间, 那么检查点进程被触发。检查点进程一旦被触发,将通知DBWn、生程按检查点队列顺序将脏 数据写入数据文件,从而缩短了最后检查点位置与联机Redo日志间的距离,减少了实例恢复 所需的时间 4)直接使用ALTER SYSTEM CHECKPOINT命令实现 5)达到LOG_CHECKPOINT_TIMEOUT的延迟时 6)当前Redo日志文件中已存在了大小为(LOG_CHECKPOINT_INTERVAL*OS块的大小(Bytes))的 数据 7)开始结束备份表空间等 在检查点期间会发生以下操作: 1)DBWn将缓冲区缓存中所有已修改的数据库块写回到数据文件中 2)检查点进程会更新所有数据文件的文件头,以反映上一个检查点发生的时间(SCN) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ARCn(Archiver Process,归档进 程) |
ora_arc0_ora11g ora_arc1_ora11g |
ARCn的工作是当LGWR把联机Redo日志文件填满后,ARCn负责把Redo日志文件的内 容复制到其他地方。联机Redo日志文件是被用来做实例恢复的时候恢复数据文件,而归档日 志足被用来在介质恢复的时候,恢复数据文件。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 续表 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 进程 | 表现形式 | 描述 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DBWn(Database Writer Process,数据库写进程) |
ora_dbw0_ora11g | DBWn负责把缓冲区的脏数据写到磁盘上,该动作由CKPT进程决定,所以, COMMIT后数据不一定会被立即写进磁盘。但是,若LGWR出现故障,则DBWn 依然会不听CKPT命令而进行罢工的。因为Oracle在将数据缓存区数据写到磁盘前, 会先进行日志缓冲区写进日志文件的操作,并耐心地等待其先完成,才会去完成这个 内存刷到磁盘的动作,这就是所谓的日志先行。在Oracle发生Switch Log Files的时 候,会发生Checkpoint。在Checkpoint发生后,在Redo日志中的数据就可以被覆盖 了。如果Redo日志被填满,且要重新利用Redo日志来存放新的数据时,而此时 Checkpoint还未完成,那么Oracle就会返回“Checkpoint not complete”。DBWn进程 工作的触发点有: 1)当Buffer Cache中缺少用于写入数据的Clean Block的时候,DBWn会开始将 一些脏块(Dirty Block)写入文件中,清理出一些可以使用的Clean Block 2)周期性的Checkpoint写入,当CKPT进程进行检查点的时候,DBWn会启动进 行写入 3)每3s检查一次是否有脏块需要写入 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LGWR(Log Writer Process, 日志写进程) |
ora_lgwr_ora11g | LGWR是把SGA中Redo Log Buffer的信息写到Redo日志文件的进程。LGWR 必须记录下所有从数据缓存区写进数据文件的动作,工作任务相当繁重。由于要顺序 记录情况下保留的日志才有意义,多进程难以保证顺序,因此LGWR只能采用单进 程。LGWR会在下面情况下被触发: 1)用户发出提交命令(COMMIT) 2)每隔3s(距离上次LGWR写入操作超过3s)。 3)Redo日志缓冲区空间剩余不到2/3,即Redo Log Buffer数据超过1/3 4)Redo日志缓冲区内的数据超过1MB 5)在发生联机Redo日志切换(Log Switch)时 6)在DBWn进程将修改过的缓冲区数据写入磁盘文件时(如果相应的Redo日志 数据尚未写入磁盘) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| CJQn(Job Queue Coordinator Process,作业调 度器) |
ora_cjq0_ora11g ora_j000_ora11g |
CJQn和Jnnn负责调度与执行系统中已定义好的Job,完成一些预定义的工作,例 如完成物化视图的刷新工作 1)CJQn起到对作业队列的监控作用 2)执行作业的队列进程Jnnn(Job Queue Slave Processes),由CJQn完成调度产 生,并且执行相关的Job |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| RECO(Recoverer Process, 分布式事务恢复) |
ora_reco_ora11g | 主要用于分布式数据库的恢复(Distributed Database Recovery),适用于两阶段提 交的应用场景。该进程可以保证分布式事务的一致性,在分布式事务中,所有数据库 要么同时COMMIT,要么同时ROLLBACK。在分布式数据库中,RECO进程可以自 动地解决分布式事务发生错误的情况。一个节点上的RECO进程自动地连接到没有 被正确处理事务相关的数据库上面。当RECO建立了数据库之间的连接,它会自动 地解决没有办法处理的事务,删除与该事务相关的待定的事务表中的行(清理事务表) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SMCO(Space Management Coordinator Process,空间管 理协调器) |
ora_smco_ora11g | SMCO是空间管理主进程,负责空间管理协调工作,负责动态执行空间的分配和 回收。它将生成从进程Wnnn以执行这些任务 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| QMNC(AQ Coordinator Process,高级队列协调进 程) |
ora_qmnc_ora11g | QMNC进程对于AQ表来说就相当于CJQO进程之于作业表。QMNC进程会监视 高级队列,并警告从队列中删除等待消息的“出队进程”(dequeuer):已经有一个消 息变为可用。QMNC和Qnnn还要负责队列传播(Propagation),也就是说,能够将 在一个数据库中入队(增加)的消息移到另一个数据库的队列中,从而实现出队 (Dequeueing) Qnnn进程对于QMNC进程就相当于Jnnn进程与CJQO进程的关系。QMNC进程 要通知Qnnn进程需要完成什么工作,Qnnn进程则会处理这些工作 QMNC和Qnnn进程是可选的后台进程。参数AQ_TM_PROCESSES可以指定最 多创建10个这样的进程(分别名为Q000,…,Q009),以及一个QMNC进程。如 果AQ_TM_PROCESSES设置为0,就没有QMNC或Qnnn进程。不同于作业队列所 用的Jnnn进程,Qrmn进程是持久的。如果将AQ_TM_PROCESSES设置为10,数 据库启动时可以看到10个Qnnn进程和一个QMNC进程,而且在实例的整个生存期 中这些进程都存在 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MARK(Mark AU for Resynchronization Coordinator Process,为重新 同步协调器标记分配单元) |
ora_mark_ora11g | 当磁盘出现故障时将会脱机,从而导致写入内容丢失。在这种情况下,此进程会 将ASM分配单元(AU)标记为陈旧(stale) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 续表 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 进 程 | 表现形式 | 描 述 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PSP0(Process Spawner Process,进程生成器) |
ora_psp0_ora11g | 当数据库实例或ASM实例启动后,用于产生其他后台进程 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VKTM(Virtual Keeper of Time Process,虚拟计时器 进程) |
ora_vktm_ora11g | 这个进程用于提供一个数据库的时钟,每秒更新:或者作为参考时间计数器,这 种方式每20ms更新一次,仅在高优先级时可用。在系统时间出现异常或变化时, VKTM进程还会检测这些变化,提醒用户,尤其是在RAC环境中,时间的偏移和变 化极有可能导致系统故障。通过VKTM进程,数据库可以降低和操作系统的交互 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GENO(General Task Execution Process,通用任 务执行进程) |
ora_gen0_ora11g | 主要是分担另外某个进程的阻塞处理 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DIAG(Diagnostic Capture Process,诊断捕获进程) |
ora_diag_ora11g | 执行诊断、转储跟踪文件以及执行全局oradebug命令,它会负责监视实例的整体 状况,捕获处理实例失败时所需的信息并记录 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DBRM(Database Resource Manager Process,数据库资 源管理器进程) |
ora_dbrm_ora11g | 为数据库实例配置资源计划,执行资源计划和其他与资源管理器相关的任务 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DIA0(Diagnostic Process, 诊断进程0) |
ora_dia0_ora11g | 检测挂起情况和死锁。将来可能会引入多个进程,因此将名称设置为DIA0。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

| 分类 | 简介 | 发生时机 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 完全检 查点 (FULL Checkp oint) |
线程检查点 (Thread Checkpoint)、 数据库检查点 (Database Checkpoint) |
数据库将所有在数据缓冲区 内由Redo修改过的数据写入磁 盘中,这个线程检查点在所有的 实例中的集合称为数据库检查点 (Database Checkpoint) |
1)数据库一致性关闭的时候(IMMEDIATE、TRANSACTION、 NORMAL或选项SHUTDOWN) 2)执行ALTER SYSTEM CHECKPOINT语句的时候 3)在线日志切换的时候(ALTER SYSTEM SWITCH LOGFILE) 4)执行ALTER DATABASE BEGIN BACKUP语句的时候 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 表空间和数据 文件检查点 (Tablespace AndData File Checkpoint) |
表空间的检查点是数据文件 检查点的集合,每个数据文件都 在这个表空间之内。将执行属于 该表空间的所有数据文件的一个 检查点操作 |
1)将一个表空间设置为只读的方式 2)将一个表空间设置为OFFLINE 3)数据文件大小变化的时候 4)执行ALTER TABLESPACE xxx BEGIN BACKUP的时候 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 增量检查点(Incremental Checkpoint) |
增量检查点是线程检查点的 一种,是为了避免联机Redo日 志切换的时候需要写入大量的脏 数据到磁盘中。DBWn至少每3s 检查一次看是否有数据要写入磁 盘中,当DBWn进程将脏数据写 入磁盘中时,会推进了检查点的 位置,从而导致CKPT进程将检 查点位置信息写入控制文件 (Control File)中,但是不会写入 数据文件头(Data File Headers) 中 |
1)恢复需求设定(FAST_START_MTTR_TARGET)。根据参数FAST_ START_MTTR_TARGET的设置来确定。如果内存中产生的Dirty Buffer 所需的恢复时间(estimated_mttr)到达FAST_START_MTTR_TARGET 的指定时间,那么检查点进程被触发。检查点进程一旦被触发,将通知 DBWn进程按检查点队列顺序将脏数据写入数据文件,从而缩短了最后 检查点位置与联机Redo日志间的距离,减少了实例恢复所需的时间 2)LOG_CHECKPOINT_INTERVAL参数值 3)达到LOG_CHECKPOINT_TIMEOUT的延迟时 4)最小的日志文件大小,当前Redo日志文件中已存在了大小为 (LOG_CHECKPOINT_INTERVAL*OS块的大小(Bytes))的数据 5)Buffer Cache中脏块的数量 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 其他 | 其他的检查点包括实例和介 质恢复检查点,当SCHEMA对 象被DROPPED或TRUNCATED 时候的检查点 |
DROP、TRUNCATE等 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||






 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题