1. [说明]
散列文件的存储单位称为桶(Bucket)。假如一个桶能存放m个记录,当桶中已有m个同义词(散列函数值相同)的记录时,存放第m+1个同义词会发生“溢出”。此时需要将第m+1个同义词存放到另一个称为“溢出桶”的桶中。相对地,称存放前m个同义词的桶为“基桶”。溢出桶和基桶大小相同,用指针链接。查找指定元素记录时,首先在基桶中查找。若找到,则成功返回;否则沿指针到溢出桶中进行查找。
例如,设散列函数为Hash(Key)=Key mod 7,记录的关键字序列为15,14,21,87,96,293,35,24,149,19,63,16,103,77,5,153,145,356,51,68,705,453,建立的散列文件内容如下图所示。
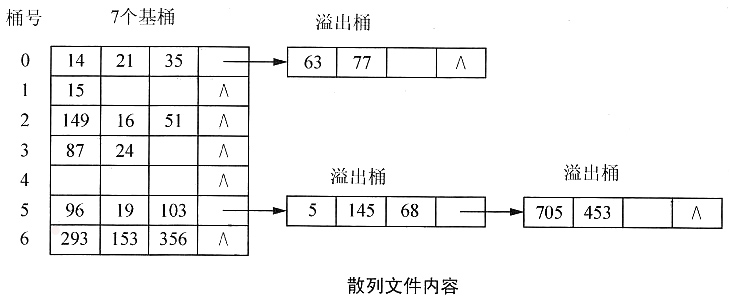
为简化起见,散列文件的存储单位以内存单元表示。
函数InsertToHashTable(int NewElemKey)的功能是:若新元素NewElemKey正确插入散列文件中,则返回值1;否则返回值0。
采用的散列函数为Hash(NewElemKey)=NewElemKey%P,其中P设定基桶数目。
函数中使用的预定义符号如下:
#define NULLKEY -1 /*散列桶的空闲单元标识*/
#define P 7 /*散列文件中基桶的数目*/
#define ITEMS 3 /*基桶和溢出桶的容量*/
typedef struct BucketNode {/*基桶和溢出桶的类型定义*/
int KeyData [ITEMS];
struct BucketNode *Link;
} BUCKET;
BUCKET Bucket [P]; /*基桶空间定义*/
函数InsertToHashTable代码如下:
int InsertToHashTable(int NewElemKey) {
/*将元素NewElemKey插入散列桶中,若插入成功则返回0,否则返回-1*/
/*设插入第一个元素前基桶的所有KeyData[]、Link域已分别初始化为NULLKEY、NULL*/
int Index; /*基桶编号*/
int i, k;
BUCKET *s, *front, *t;
______;
for (i = 0; i < ITEMS; i++) /*在基桶查找空闲单元,若找到则将元素存入*/
if (Bucket[Index]. KeyData[i] == NULLKEY) {
Bucket[Index]. KeyData [i] = NewElemKey;
break;
}
if (______) return 0;
/*若基桶已满,则在溢出桶中查找空闲单元,若找不到则申请新的溢出桶*/
______;
t = Bucket [Index]. Link;
if (t != NULL) { /*有溢出桶*/
while (t !=NULL) {
for (k=0; k<ITEMS; k++)
if (t→KeyData [k] == NULLKEY) { /*在溢出桶链表中找到空闲单元*/
t→KeyData [k] = NewElemKey;
break;
} /*if*/
front=t;
if (______)t = t; Link;
else break;
} /*while*/
} /*if*/
if (______) { /*申请新溢出桶并将元素存入*/
s = (BUCKET *) malloc (sizeof (BUCKET));
if (!s) return -1;
s→Link = NULL;
for (k=0; k<ITEMS; k++)
s→KeyData [k] = NULLKEY;
S→KeyData[0]=NewElemKey;
______;
} /*if*/
return 0;
} /*InsertToHashTable*/
Index=NewElemKey%P或Index=Hash(NewElemKey)
i<ITEMS
front=&Bucket[index]或front=Bucket+Index
k==ITEMS或k>=ITEMS
t==NULL
front→Link=s






 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题