一、单选题4. 当被测量的函数形式为
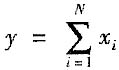
,各输入量间不相关时,合成标准不确定度u
c(y)可用______式计算。
A.
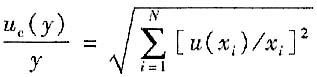
B.
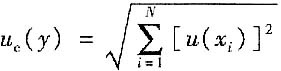
C.
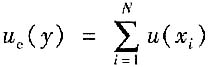
D.
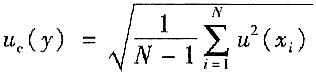
A B C D
B
[解析] 根据函数关系为线性相加的,不是相对量的方和根(不是答案A),也不是标准不确定度的线性相加(不是答案C),更不是答案D。所以正确答案为B。
16. 当被测量的函数形式为:y=A
1X
1+A
2X
2+…+A
NX
N,且各输入量不相关时,合成标准不确定度u
c(y)为______。
A.
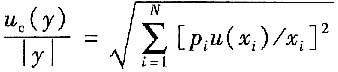
B.
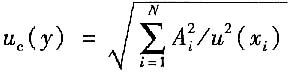
C.
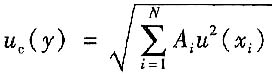
D.
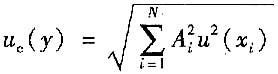
A B C D
二、思考题1. 什么是概率分布?
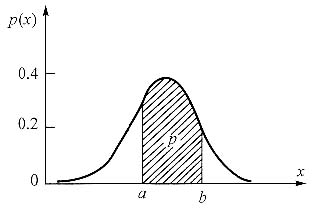
概率分布是一个随机变量取任何给定值或属于某一给定值集的概率随取值而变化的函数,该函数称为概率密度函数。概率分布通常用概率密度函数随随机变量变化的曲线来表示,如下图所示。
2. 试写出测量值X落在区间[a,b]内的概率p与概率密度函数的函数关系式,并说明其物理意义。
测量值X落在区间[a,b]内的概率p可用下式计算
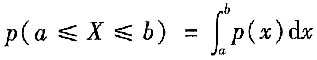
式中,p(x)为概率密度函数,数学上积分代表面积。
由此可见,概率p是概率分布曲线下在区间[a,b]内包含的面积,又称包含概率或置信水平。当p=0.9,表明测量值有90%的可能性落在该区间内,该区间包含了概率分布下总面积的90%。在(-∞~+∞)区间内的概率为1,即随机变量在整个值集的概率为1。当p=1(即概率为1)表明测量值以100%的可能性落在该区间内,也就是可以相信测量值必定在此区间内。
3. 表征概率分布的特征参数是哪些?
表征概率分布的特征参数有期望和方差(或标准差)。
(1)期望——位置参数,表明概率密度函数曲线的位置,一般表示平均值的大小;
(2)方差(或标准差)——形状参数,表明概率密度函数曲线的形状(平缓或尖锐),表示值集或样本集的分散性。
4. 期望和标准偏差分别表征概率分布的哪些特性?
期望和方差是表征概率分布的两个特征参数。由于方差不便使用,通常用期望μ和标准偏差σ来表征一个概率分布。μ和σ对正态分布函数曲线的影响见下图,μ影响概率分布曲线的位置;σ影响概率分布曲线的形状,表明测量值的分散性。
期望与标准偏差都是以无穷多次测量的理想情况定义的,无法由测量得到μ,σ
2和σ,因此都是概念性的术语。
5. 有限次测量时,期望和标准偏差的估计值分别是什么?
算术平均值
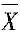
是有限次测量时概率分布的期望μ的估计值。
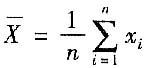
用有限次测量的数据得到的标准偏差的估计值称为实验标准偏差,用符号s表示。实验标准偏差s是有限次测量时标准偏差σ的估计值。最常用的估计方法是贝塞尔公式法,即在相同条件下,对被测量X作n次重复测量,每次测得值为x
i,测量次数为n,则实验标准偏差按下式估计

式中:
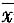
——n次测量的算术平均值;

——第i次测量的测得值。
在给出标准偏差的估计值时,自由度越大,表明估计值的可信度越高。
6. 正态分布时,测得值落在μ±kσ区间内,k=2时的概率是多少?是如何得来的?
正态分布时,测量值落在μ±kσ区间内,k=2时的概率是95.45%。
依题意,已知包含区间为[-2σ,2σ],可通过计算正态分布概率密度函数的定积分得到,也可查表(见教材表3-8)得到。
测量值x落在[a,b]区间内的概率为
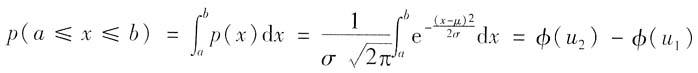
式中,μ=(x-μ)/σ。
通常将
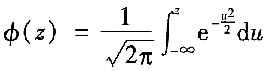
称为标准正态分布函数,函数关系值见下表。
| 标准正态分布函数表(摘录)
|
| z
|
1.0
|
2.0
|
2.58
|
3.0
|
|
0.84134
|
0.97725
|
0.99506
|
0.99865
|
令δ=x-μ,若设|δ|≤3σ,即u=δ/σ=±3,u
1=z
1=-3,u
2=z
2=+3,按上述概率公式计算
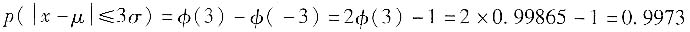
同样,
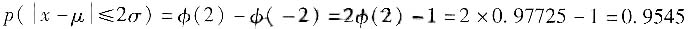
由此可见,区间[-2σ,2σ]在概率分布曲线下包含的面积约占概率分布总面积的95%。也就是:当k=2时,包含概率为95.45%。
用同样的方法可以计算得到正态分布时测量值落在[u-kσ,u+kσ]置信区间内的包含概率,如下表所列。包含概率与k值有关,在概率论中k被称为置信因子。
| 正态分布时包含概率与包含因子k的关系
|
| 包含概率p
|
0.5
|
0.6827
|
0.9
|
0.95
|
0.9545
|
0.99
|
0.9973
|
| 包含因子k
|
0.675
|
1
|
1.645
|
1.96
|
2
|
2.576
|
3
|
7. 有哪些常用的概率分布?它们的区间半宽度与包含因子分别有什么关系?
常用的概率分布的区间平宽度与包含因子的关系见下表:
8. 什么叫相关?表示相关性的参数是什么?
如果两个随机变量X和Y,其中一个量的变化会导致另一个量的变化,就说这两个量是相关的。
例如:Y=X1+X2中,X2=bX1,则X2随X1变化而变化,说明量X2与量X1是相关的。表示相关性的参数有协方差和相关系数。
9. 协方差与相关系数是什么关系?相关系数有什么特点?
协方差V(X,Y)与相关系数ρ(X,Y)的关系是:
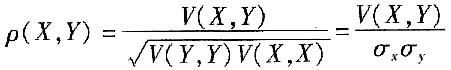
协方差估计值s(x,y)与相关系数估计值r(x,y)的关系
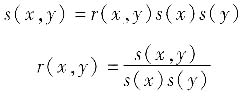
相关系数是一个纯数字,相关系数的值在-1到+1之间,它表示两个量的相关程度,通常比协方差更直观。相关系数为零,表示两个量不相关;相关系数为+1,表明X与Y正全相关(正强相关),即随着X增大Y也增大;相关系数为-1,表明X与Y负全相关(负强相关),即随着X增大Y变小。
10. 如何得到协方差与相关系数的估计值?协方差估计值及相关系数估计值分别用什么符号表示?
有限次测量时协方差的估计值用s(x,y)表示,按下式计算

式中:
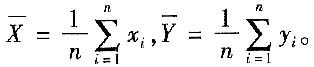
有限次测量时的算术平均值
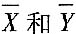
的协方差估计值用
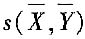
表示,按下式计算
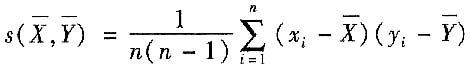
相关系数的估计值用r(x,y)表示,用下式求得
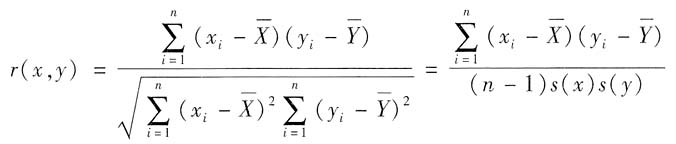
式中,s(x)和s(y)分别为X和Y的实验标准偏差。
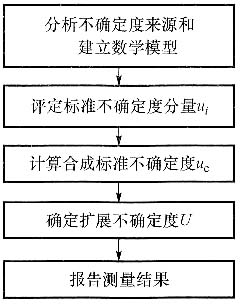
11. 什么是评定测量不确定度的GUM法?一般,GUM法评定测量不确定度有哪些步骤?
评定测量不确定度的GUM法是指按照JJF 1059.1—2012《测量不确定度评定与表示》方法评定测量不确定度,称为CUM评定方法或GUM法。
GUM法评定测量不确定度步骤有:
(1)明确被测量,必要时给出被测量的定义及测量过程的简单描述;
(2)分析不确定度来源并写出测量模型;
(3)评定测量模型中的各输入量的标准不确定度u(x
i),计算灵敏系数c
i,从而给出与各输入量相对应的输出量y的不确定度分量u
i(y)=|c
i|u(x
i);
(4)计算合成标准不确定度u
c(y),计算时应考虑各输入量之间是否存在值得考虑的相关性,对于非线性数学模型则应考虑是否存在值得考虑的高阶项;
(5)列出不确定度分量的汇总表,表中应给出每一个不确定度分量的详细信息;
(6)对被测量的概率分布进行估计,并根据概率分布和所要求的包含概率p确定包含因子k
p;
(7)在无法确定被测量y的概率分布时,或该测量领域有规定时,也可以直接取包含因子k=2;
(8)由合成标准不确定度u
c(y)和包含因子k或k
p的乘积,分别得到扩展不确定度U或U
p;
(9)给出测量不确定度的最后陈述,其中应给出关于扩展不确定度的足够信息。利用这些信息,至少应该使用户能从所给的扩展不确定度进而评定其测量结果的合成标准不确定度。
通常,不确定度评定的流程如下图所示。
12. 测量不确定度的来源可以从哪些方面考虑?
测量中可能导致不确定度的来源一般有:
(1)被测量的定义不完整;
(2)复现被测量的测量方法不理想;
(3)取样的代表性不够,即被测样本不能代表所定义的被测量;
(4)对测量过程受环境影响的认识不恰如其分或对环境的测量与控制不完善;
(5)对模拟式仪器的读数存在人为偏移;
(6)测量仪器的计量性能(如灵敏度、鉴别力阈、分辨力、死区及稳定性等)的局限性;
(7)测量标准或标准物质提供的量值的不准确;
(8)引用的数据或其他参量值的不准确;
(9)测量方法和测量程序的近似和假设;
(10)在相同条件下被测量在重复观测中的变化。
通常,在分析测量结果的不确定度来源时,可以从测量仪器、测量环境、测量方法、被测量等方面全面考虑,应尽可能做到不遗漏,不重复。特别应考虑对测量结果影响较大的不确定度来源。
13. 什么是测量模型?建立测量模型时要注意什么?
测量模型是指测量结果与其直接测量的量、引用的量以及影响量等有关量之间的数学关系。
当被测量Y由N个其他量X1,X2,…,XN的函数关系确定时,被测量的测量模型为
Y=f(X1,X2,…,XN)
被测量的测量结果称为输出量,输出量Y的估计值y是由各输入量Xi的估计值xi按测量模型确定的函数关系f计算得到
y=f(x1,x2,…,xN)
建立测量模型要注意下列几点:
(1)测量模型可以用已知的物理公式(包括化学分析的计算公式)得到,也可以用实验方法确定,甚至只用数值方程给出。
(2)测量模型不是唯一的,对于同一个被测量采用不同的测量方法和不同的测量程序,就会有不同的测量模型。
(3)测量模型不一定是完善的,它与人们对规律的认识程度有关。为了能在测量模型中充分反映实际的影响量,尽可能采用长期积累的数据建立经验模型。
(4)有时被测量Y的输入量X1,X2,…,XN本身又取决于其他量,它们各自与其他量间有函数关系,还可能包含对系统影响修正的修正值或修正因子,导致十分复杂的函数关系。这时候,测量模型可能是一系列关系式。
(5)如果数据表明测量模型中没有考虑某个具有明显影响的影响量时,应在模型中增加输入量,直至测量结果满足测量准确度的要求。
14. 标准不确定度有哪几种评定方法?
标准不确定度的评定方法有两种:
(1)标准不确定度分量的A类评定
(2)标准不确定度分量的B类评定。
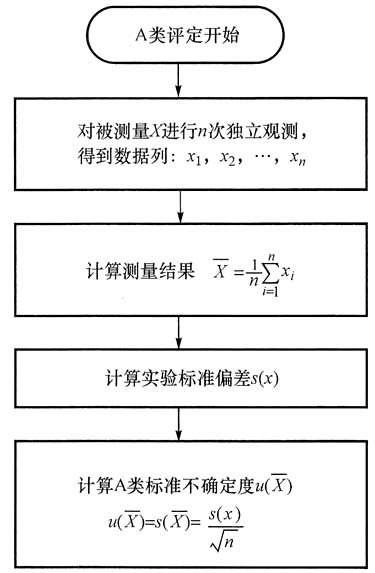
15. 如何用A类评定方法评定标准不确定度分量?
(1)基本的标准不确定度A类评定流程(如下图)
(2)测量过程的A类标准不确定度评定
对一个测量过程,如果采用核查标准核查的方法使测量过程处于统计控制状态,则该测量过程的实验标准偏差为合并样本标准偏差s
p。
若每次核查时测量次数n相同(即自由度相同),每次核查时的样本标准偏差为s
i,共核查k次,则合并样本标准偏差s
p为
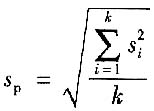
此时,s
p的自由度ν=(n-1)k。
则在此测量过程中,测量结果的A类标准不确定度为
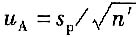
式中,n'为获得测量结果时的测量次数。
(3)规范化常规测量时A类标准不确定度评定
规范化常规测量是指已经明确规定了测量程序和测量条件下的测量,如日常按检定规程进行的大量同类被测件的检定,当可以认为对每个同类被测量的实验标准偏差相同时,通过累积的测量数据,计算出自由度充分大的合并样本标准偏差,以用于评定每次测量结果的A类标准不确定度。
在规范化的常规测量中,测量m个同类被测量,得到m组数据,每组测量n次(每组测量次数相同),第j组第i次测量值为x
ij,第j组的平均值为

,则合并样本标准偏差s
p为
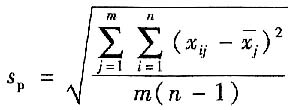
对每个量的测量结果
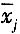
的A类标准不确定度
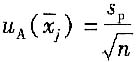
自由度为ν=m(n-1)。
若对每个被测件的测量次数n
j不同,即各组的自由度ν
j不等,各组的实验标准偏差为s
j,则
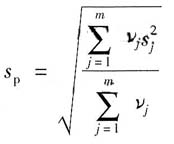
式中,ν
j=n
j-1。
对于常规的计量检定或校准,当无法满足n≥10时,为使得到的实验标准差更可靠,如果有可能,建议采用合并样本标准差s
p作为由重复性引入的标准不确定度分量。
(4)由最小二乘法拟合的最佳直线上得到的预期值的A类标准不确定度评定
由最小二乘法拟合的最佳直线的直线方程:y=a+bx
预期值y
j的实验标准偏差为

式中,r(a,b)为a和b的相关系数;s
a,s
b和s
x分别为a,b和x的实验标准偏差。
预期值y
j的A类标准不确定度为u
A(y
j)=s
p(y
j)。
16. 规范化常规测量时可以如何进行A类标准不确定度评定?
规范化常规测量是指已经明确规定了测量程序和测量条件下的测量,如日常按检定规程进行的大量同类被测件的检定,当可以认为对每个同类被测量的实验标准偏差相同时,通过累积的测量数据,计算出自由度充分大的合并样本标准偏差,以用于评定每次测量结果的A类标准不确定度。
在规范化的常规测量中,测量m个同类被测量,得到m组数据,每组测量n次(每组测量次数相同),第j组第i次侧量值为x
ij,第j组的平均值为
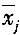
,则合并样本标准偏差s
p为
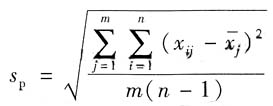
对每个量的测量结果
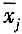
,的A类标准不确定度
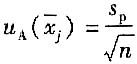
式中:n——每组的组内测量次数。
自由度为ν=m(n-1)。
若对每个被测件的测量次数n
j不同,即各组的自由度ν
j不等,各组的实验标准偏差为s
j,则
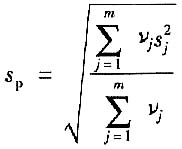
式中,ν
j=n
j-1。
对于常规的计量检定或校准,当无法满足n≥10时,为使得到的实验标准差更可靠,如果有可能,建议采用合并样本标准偏差s
p作为由重复性引入的标准不确定度分量。
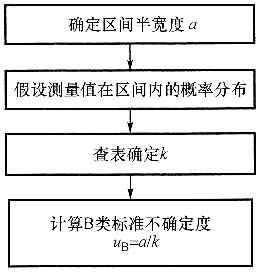
17. 试述标准不确定度B类评定的步骤?
标准不确定的B类评定是借助于一切可利用的有关信息进行科学判断,得到估计的标准偏差。可概括为三个步骤:
(1)根据有关信息或经验,判断被测量的可能值区间(-a,a);
(2)假设被测量值的概率分布;
(3)根据概率分布和要求的置信水平p估计置信因子k,则B类标准不确定度u
B为
u
B=a/k
式中,a为被测量可能值区间的半宽度;k为置信因子或包含因子。
标准不确定度的B类评定流程如下图所示。
18. 试述B类评定时可能的信息来源及如何确定可能值的区间半宽度?
区间半宽度a值是根据有关的信息确定的。
(1)一般情况下,可利用的信息包含:
①以前的观测数据;
②对有关技术资料和测量仪器特性的了解和经验;
③生产部门提供的技术说明文件(制造厂的技术说明书);
④校准证书、检定证书、测试报告或其他提供的数据、准确度等级等;
⑤手册或某些资料给出的参考数据及其不确定度;
⑥规定测量方法的校准规范、检定规程或测试标准中给出的数据;
⑦其他有用信息。
(2)确定可能值的区间半宽度可以采取如下方法:
①制造厂的说明书给出测量仪器的最大允许误差为±Δ,并经计量部门检定合格,则可能值的区间为(-Δ,+Δ),区间的半宽度为
a=Δ
②校准证书提供的校准值,给出了其扩展不确定度为U,则区间的半宽度为
a=U
③由手册查出所用的参考数据,同时给出该数据的误差不超过±Δ,则区间的半宽度为
a=Δ
④由有关资料查得某参数X的最小可能值为a
-和最大可能值为a
+,区间半宽度可以用下式确定
⑤数字显示装置的分辨力为末位1个数字所代表的量值δ
x,则取
a=δx/2
⑥当测量仪器或实物量具给出准确度等级时,可以按检定规程或有关规范所规定的该等别或级别的最大允许误差或测量不确定度进行评定;
⑦根据过去的经验判断某值不会超出的范围来估计区间半宽度n值;
⑧必要时,用实验方法来估计可能的区间。
19. B类评定时,如何假设可能值的概率分布和确定k值?
(1)B类评定时可按以下方法假设可能值的概率分布
①被测量受许多相互独立的随机影响量的影响,这些影响量变化的概率分布各不相同,但各个变量的影响均很小时,被测量的随机变化服从正态分布。
②如果有证书或报告给出的扩展不确定度是U
90、U
95或U
99,除非另有说明,可以按正态分布来评定B类标准不确定度。
③一些情况下,只能估计被测量的可能值区间的上限和下限,测量值落在区间外的概率几乎为零。若测量值落在该区间内的任意值的可能性相同,则可假设为均匀分布。
④若落在该区间中心的可能性最大,则假设为三角分布。
⑤若落在该区间中心的可能性最小,而落在该区间上限和下限处的可能性最大,则假设为反正弦分布。
⑥对被测量的可能值落在区间内的情况缺乏了解时,一般假设为均匀分布。
实际工作中,可依据同行专家的研究和经验来假设概率分布。例如:无线电计量中失配引起的不确定度为反正弦分布;几何量计量中度盘偏心引起的测角不确定度为反正弦分布;测量仪器最大允许误差、分辨力、数据修约、度盘或齿轮回差等导致的不确定按均匀分布考虑;两个量值之和或差的概率分布为三角分布;按级使用量块时,中心长度偏差导致的概率分布为两点分布。
(2)k值的确定可按下述方法
①已知扩展不确定度是合成标准不确定度的若干倍时,则该倍数(包含因子)就是k值。
②假设概率分布后,根据要求的置信概率查表得到置信因子k值。
例如:如果数字显示仪器的分辨力为δ
x,则区间半宽度a=δ
x/2,可假设为均匀分布,查表得k=
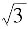
,由分辨力引起的标准不确定度分量为

若某数字电压表的分辨力为1μV(即最低位的一个数字代表的量值),则由分辨力引起的标准不确定度分量为
u(V)=0.29×1μV=0.29μV
被测仪器的分辨力会对测量结果的重复性测量有影响。在测量不确定度评定中,当重复性引入的标准不确定度分量大于被测仪器的分辨力所引入的不确定度分量时,可以不考虑分辨力所引入的不确定度分量。但当重复性引入的不确定度分量小于被测仪器的分辨力所引入的不确定度分量时,应该用分辨力引入的不确定度分量代替重复性分量。若被测仪器的分辨力为δ
x,则分辨力引入的标准不确定度分量为0.296δ
x。
(3)常用的概率分布与置信因子的关系
| 正态分布的置信因子k值与概率p的关系
|
| p
|
0.50
|
0.90
|
0.95
|
0.99
|
0.9973
|
| k
|
0.676
|
1.64
|
1.96
|
2.58
|
3
|
20. 如何计算出B类标准不确定度的自由度?
B类标准不确定度的自由度可由下式估计
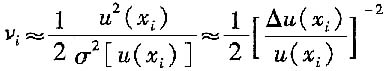
σ[u(x
i)]/u(x
i)称为u(x
i)的相对标准不确定度,估计值为Δu(x
i)/u(x
i),可称为不可信程度。根据经验,按所依据的信息来源的不可信程度来判断u(x
i)的相对标准不确定度,然后按上式计算出自由度ν列于下表。
| B类标准不确定度的自由度估计
|
| Δu(xi)/u(xi)
|
0
|
0.10
|
0.20
|
0.25
|
0.30
|
0.40
|
0.50
|
| ν
|
∞
|
50
|
12
|
8
|
6
|
3
|
2
|
21. 试写出测量不确定度的传播律,并说明公式中各项的含义。
测量不确定度的传播律如下:
当被测量的测量结果y的数学模型为线性函数y=f(x
1,x
2,…,x
N)时,测量结果y的合成标准不确定度u
c(y)按下式计算,此式称为“不确定度传播律”。
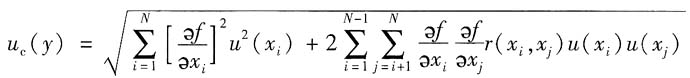
式中:y——输出量的估计值,即被测量的测量结果;
x
i,x
j——输入量的估计值,i≠j;
N——输入量的数量;
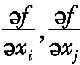
——偏导数,又称灵敏系数,可表示为c
i,c
j;
u(x
i),u(x
j)——输入量x
i和x
j的标准不确定度;
r(x
i,x
j)——输入量x
i与x
j的相关系数估计值;
r(x
i,x
j)u(x
i)u(x
j)=u(x
i,x
j)——输入量x
i与x
j的协方差估计值。
注:当测量模型为非线性函数时,可采用泰勒级数展开,舍去高次项后得到近似的线性函数。
22. 输入量间不相关时计算合成标准不确定度有哪些简化公式?
(1)当各输入量间不相关,即r(x
i,x
j)=0时,计算合成标准不确定度公式简化形式为

若设u
i(y)是测量结果y的标准不确定度分量
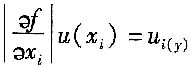
则u
c(y)由被测量y的标准不确定度分量合成时,可用下式评定
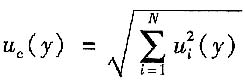
对于直接测量,可简单写成
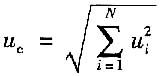
(2)当被测量的函数形式为:y=A
1X
1+A
2X
2+…+A
NX
N,且各输入量不相关时,合成标准不确定度u
c(y)为
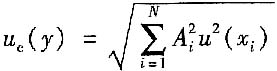
(3)当被测量的函数形式为:
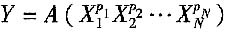
,且各输入量不相关时,合成标准不确定度u
c(y)为
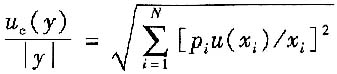
如果上式中p
i=1,则被测量的测量结果的相对合成标准不确定度是各输入量的相对合成标准不确定度的方和根值

23. 输入量间正强相关时计算合成标准不确定度有什么特点?
当所有输入量都相关,且输入量间相关系数均为+1时,称为正强相关,计算合成标准不确定度u
c(y)的公式简化为
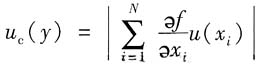
当所有输入量都相关,且相关系数为+1,灵敏系数为+1时,合成标准不确定度u
c(y)为
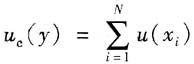
(注:当灵敏系数为-1时,上式不适用)
由此可见,当输入量都正强关系,且灵敏系数均为+1时,合成标准不确定度是各输入量标准不确定度分量的代数和。也就是说,强相关时不再是方和根法合成。
24. 用什么方法可以获得协方差和相关系数的估计值?
(1)在以下情况时可取协方差为零或忽略不计
①x
i与x
j中任一个可作为常数处理;
②在不同实验室用不同测量设备、在不同时间测得的量值;
③独立测量的不同量的测量结果。
(2)用同时观测两个量的方法确定协方差估计值
对两个输入量X
i及X
j进行同时重复观测,设x
ik,x
jk分别是输入量X
i及X
j的观测值。k为测量次数(k=1,2,…,n)。
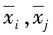
分别为第i个输入量和第j个输入量的k次测量的算术平均值;x
i与x
j的协方差估计值可由下式计算
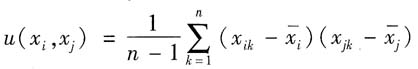
(3)同时观测两个量的方法确定相关系数的估计值
根据对x和y两个量同时测量的n组测量数据,相关系数的估计值按下式计算
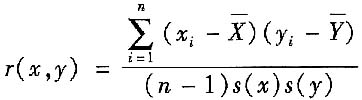
式中,s(x)和s(y)分别为x和y的实验标准偏差。
(4)用经验公式估计相关系数
如果两个输入量x
i和x
j相关,x
i变化δ
i会使x
j相应变化δ
j,则x
i和x
j的相关系数可用如下经验公式估计
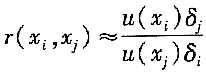
式中,u(x
i)和u(x
j)分别为x
i和x
j的标准不确定度。
(5)当两个量均因与同一个量有关而相关时,协方差的估计方法
设x
i=F(g),x
j=G(q)
式中,q为使x
i与x
j相关的变量Q的估计值,F,Q分别表示两个量与q的测量函数。则x
i与x
j的协方差按下式计算
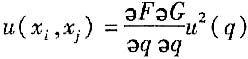
如果有多个变量使x
i与x
j相关,当
x
i=F(q
1,q
2,…,q
L),x
j=G(q
1,q
2,…,q
L)时,则协方差按下式计算
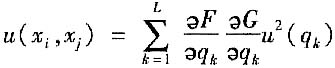
(6)采用适当方法去除相关性
①将引起相关的量作为独立的附加输入量进入测量模型;
②采取有效措施变换输入量。
25. 扩展不确定度U和U
p有什么区别?
(1)扩展不确定度U由合成标准不确定度u
c乘包含因子k得到
U=ku
c 测量结果可表示为:Y=y±U,y是被测量Y的最佳估计值,被测量Y的可能值以较高的包含概率落在[y-U,y+U]区间内,即y-U≤Y≤y+U,扩展不确定度U是该统计包含区间的半宽度。
(2)当要求扩展不确定度所确定的区间具有接近于规定的包含概率p时,扩展不确定度用符号U
p表示
U
p=k
pu
c式中,k
p是包含概率为p时的包含因子。
主要区别:
U——不与概率相联系,一般取k=2,可用于普通情况。
U
p——与概率相联系,k=t(ν
eff),用于要求比较高的情况,但通常须满足:
①测量模型为线性或非线性不显著;
②合成标准不确定度(或者输出量)的分布接近正态分布或t分布。
(3)当合成分布为非正态分布时k
p的选取
如果不确定度分量很少,且其中有一个分量起主要作用,合成分布就主要取决于此分量的分布,可能为非正态分布。
①当要求确定U
p,而合成的概率分布为非正态分布时,应根据概率分布确定k
p值。
例如:若合成分布接近均匀分布,则对p=0.95的k
p为1.65,对p=0.99的k
p为1.71。若合成分布接近两点分布,p=0.99,取k
p=1;三角分布,p=0.99,取
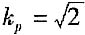
;反正弦分布,p=0.99,取k
p=
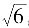
。
②实际上,当合成分布接近均匀分布时,为了便于测量结果间进行比较,有时约定仍取k为2。这种情况下给出扩展不确定度时,包含概率远大于0.95,所以此时应注明k的值,但不必注明p的值。
26. 用什么方法确定扩展不确定度U?
扩展不确定度U由合成标准不确定度uc乘包含因子k得到
U=kuc
其中,包含因子k按以下方法选取:
包含因子k的值是根据U=kuc所确定的区间y±U需具有的置信水平来选取。k值一般取2或3。当取其他值时,应说明其来源。
为了使所有给出的测量结果之间能够方便地相互比较,在大多数情况下取k=2。当接近正态分布时,测量值落在由U=2uc所给出的统计包含区间内的概率(置信水平)约为95%。
若k=3,则由U=3Uc所确定的区间具有的包含概率(置信水平)约为99%以上。
当给出扩展不确定度U时,应注明所取的k值。
27. 用什么方法确定扩展不确定度U
p?
当明确规定包含概率时,扩展不确定度的评定方法如下:
当要求扩展不确定度所确定的区间具有接近于规定的包含概率p时,扩展不确定度用符号U
p表示
U
p=k
pu
c式中,k
p是包含概率为p时的包含因子。
(1)接近正态分布时k
p的确定
根据中心极限定理,当不确定度分量大量、独立、均匀小,其合成分布接近正态分布,此时若以算术平均值作为测量结果y,通常可假设概率分布为t分布,可以取k
p值为t值。即
k
p=t
p(ν
eff)
根据合成标准不确定度u
c(y)的有效自由度ν
eff和需要的置信水平p,查表得到的t值即置信水平为p的包含因子k
p。
扩展不确定度U
p=k
pu
c(y)提供了一个具有包含概率(置信水平)为p的区间y±U。
获得k
p的计算步骤为:
①先求得测量结果y及其合成标准不确定度u
c(y)。
②用韦尔奇-萨特思韦特公式计算u
c(y)的有效自由度ν
eff[详见教材P254式(3-77)或式(3-78)]
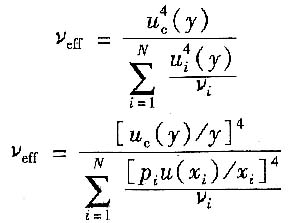
其中各输入量的标准不确定度u(x
i)的自由度ν
i按u(x
i)不同的评定方法而不同,主要计算方法如下:
a)用贝塞尔公式作A类评定时,ν=n-1;
b)用极差法作A类评定时,查表得ν值;
c)使用核查标准做测量过程控制或规范化测量作A类评定时,
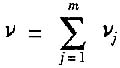
;
d)使用最小二乘法作A类评定时,ν=n-2;
e)当u(x
i)用B类评定得到时,用下式估算
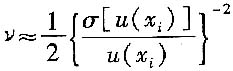
式中,
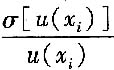
是估计B类评定u(x
i)时存在的不可靠程度。
③根据要求的置信水平p和计算得到的有效自由度ν
eff,查t分布的t值表得到t
p(ν
eff)值。
④取k
p=t
p(ν
eff),并计算U
p=k
pu
c。
(2)当合成分布为非正态分布时k
p的选取
如果不确定度分量很少,且其中有一个分量起主要作用,合成分布就主要取决于此分量的分布,可能为非正态分布。
①当要求确定U
p,而合成的概率分布为非正态分布时,应根据概率分布确定k
p值。
例如:若合成分布接近均匀分布,则对p=0.95的k
p为1.65,对p=0.99的k
p为1.71。若合成分布接近两点分布,p=0.99,取k
p=1;三角分布,p=0.99,取
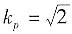
;反正弦分布,p=0.99,取k
p=
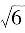
。
②实际上,当合成分布接近均匀分布时,为了便于测量结果间进行比较,有时约定仍取k为2。这种情况下给出扩展不确定度时,包含概率远大于0.95,所以此时应注明k的值,但不必注明p的值。
28. 常用的不确定度符号如何正确书写?
(1)标准不确定度的符号:u
(2)标准不确定度分量的符号:ui
(3)相对标准不确定度的符号:ur或urel
(4)合成标准不确定度的符号:uc
(5)扩展不确定度的符号:U
(6)相对扩展不确定度的符号:Ur或Urel
(7)明确规定包含概率为p时的扩展不确定度的符号:Up
(8)包含因子的符号:k
(9)明确规定包含概率为p时的包含因子的符号:kp
(10)包含概率的符号:p
(11)自由度的符号:ν
(12)合成标准不确定度的有效自由度的符号:νeff
29. 评定测量不确定度的GUM法有哪些适用条件?
GUM法的主要适用条件:
(1)可以假设输入量的概率分布呈对称分布;
(2)可以假设输出量的概率分布近似为正态分布或t分布;
(3)测量模型为线性模型、可以转化为线性模型的模型或可用线性模型近似的模型。
30. 什么是评定测量不确定度的蒙特卡洛法?用MCM评定测量不确定度有哪些步骤?
(1)蒙特卡洛法可以简述如下:
蒙特卡洛法简称MCM,MCM是采用概率分布传播的方法,即通过对输入量X
i的概率密度函数(PDF)离散抽样,由测量模型传播输入量的分布,计算获得输出量Y的PDF的离散抽样值,进而由输出量的离散分布数值直接获取输出量的最佳估计值、标准不确定度和包含区间。该输出量的最佳估计值、标准不确定度和包含区间等特性的可信程度随PDF抽样数增加可得到改善。下图描述了由输入量X
i(i=1,…,N)的PDF通过模型传播,给出输出量Y的PDF的一个过程示意。图中列出了相互独立的分别为正态分布、三角分布和正态分布的3个输入量,而输出量的PDF显示为分布不对称的情形。
(2)用MCM评定测量不确定度的步骤如下:
①McM输入
a)定义输出量Y,即被测量;
b)确定与Y相关的输入量X
1,…,X
N;
c)建立Y和X
1,…,X
n之间的测量模型Y=f(X
1,…,X
N);
d)利用可获得的信息,为X
i设定PDF,如正态分布、均匀分布等;
e)选择蒙特卡洛试验样本量的大小M。
②MCM传播
a)从输入量X
i的PDFgx
i(ξ
i)中抽取M个样本值x
ir,i=1,2,…,N,r=1,2,…,M;
b)对每个样本值(x
1r,x
2r,…,x
Nr),计算相应Y的模型值y
r=f(x
1r,x
2r,…,x
Nr),r=1,…,M。
(3)MCM输出
将这些M个模型值按严格递增次序排序,由这些排序的模型值得到输出量Y的分布函数的离散表示G。
(4)报告结果
①由G计算输出量Y的估计值y及y的标准不确定度u(y);
②由G计算在约定包含概率p时的包含区间[y
low,y
high]。
MCM使用方法详见JJF 1059.2—2012《用蒙特卡洛法评定测量不确定度》。
31. 用GUM法和MCM两种方法评定后报告结果的方式有什么区别?
用蒙特卡洛法评定测量不确定度时必须由相应的计算软件进行计算。用蒙特卡洛法评定后报告的结果不用合成标准不确定度和扩展不确定度,而是被测量的估计值y及y的标准不确定度u(y),以及在约定包含概率p时的包含区间[ylow,yhigh],包含区间不一定是对称的。
32. 为什么说GUM法依然是评定测量不确定度的最基本的方法?
JJF 1059.1—2012《测量不确定度评定与表示》中规定:有时虽然GUM法的适用条件不完全满足,当用GUM法评定的结果得到蒙特卡洛法验证时,则依然可以用GUM法评定测量不确定度。因此,GUM法依然是评定测量不确定度的最基本的方法。


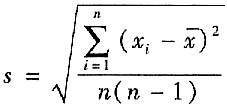
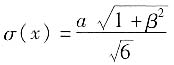
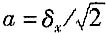


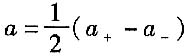




 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题