简答题1. 如何理解Maven的坐标?
Maven制定了一套规则——使用坐标进行唯一标识。Maven的坐标元素包括groupId、artifactId、version、packaging、classfier。
只要提供正确的坐标元素,Maven就能找到对应的构件,首先去本地仓库查找,没有找别再去远程仓库下载。如果没有配置远程仓库,会默认为中央仓库地址。
上述5个坐标元素中groupId、artifactId、version是必须定义的;packaging是可选的(默认为jar);而classfier是不能直接定义的,需要结合插件使用。
[考点] Maven
2. Statement中的getGeneratedKeys方法有何作用?
获取自动生成的主键并创建此Statement对象执行的结果。如果没有指定的列自动生成的键,JDBC驱动程序实现将确定最能代表自动生成的主键列。如果此Statement对象没有产生任何键,则返回空的ResultSet对象。如果创建了自动生成的键值,则会返回一个包含了自动生成键值的ResultSet对象。
[考点] JDBC相关
3. 标注SpringMVC中的控制器的注解是哪些?有何不同?
控制器的注解可用@Controller和@RestController。两者区别如下。
1)@RestController注解相当于@ResponseBody与@Controller合在一起的作用。如果只是使用@RestController注解Controller,则Controller中的方法无法返回JSP页面或者HTML,配置的视图解析器InternalResourceViewResolver不起作用,返回的内容就是return中的内容。
2)如果需要返回到指定页面,则需要用@Controller配合视图解析器才行。如果需要返回JSON、XML或自定义MediaType内容到页面,则需要在对应的方法上添加@ResponseBody注解。
[考点] SpringMVC
4. 工作中用什么工具查看或监视Tomcat的内存?
使用JDK自带的jconsole可以比较清楚地看到内存的使用情况,线程的状态,当前加载的类的总量等。
JDK自带的jvisualvm可以查看更丰富的信息。如果是分析本地的Tomcat,还可以进行内存抽样等,检查每个类的使用情况。
在Windows上使用putty+xming也可以远程查看Linux服务器上部署的Tomcat的运行情况。
[考点] Web服务器
5. MyBatis框架的执行过程是怎样的?
MyBatis框架的执行过程大体如下。
1)通过MyBatis配置文件,加载运行环境,创建全局共用的SqlSessionFactory会话工厂。
2)执行会话时,先通过SqlSessionFactory创建SqlSession。SqlSession接口对象用于执行持久化操作,可以通过这个接口来执行数据库操作命令,获取映射器和管理事务。
3)通过SqlSession执行数据库操作。
4)如果需要提交事务,执行SqlSession的commit()方法。
5)调用Session.close()关闭SqlSession,释放资源。
[考点] MyBatis
6. Swagger如何控制显示或隐藏Swagger UI?
Swagger UI为开发测试提供了很大的便利,但是在生产环境、一些演示或其他特定的环境为了安全起见,需要关闭对Swagger UI的访问。Swagger提供了两种实现这一需求的方式,开发者可以根据实际需要来选择。下面具体介绍:
1)通过给Swagger配置类添加@Profile注解实现,个人推荐用这种方式,因为它更简单。示例代码如下:
@Configuration
@EnableSwagger2
@Profile({"dev","test"})
public classSwaggerConfig{……}
@Profile注解中的{"dev","test"}对应于工程的spring.profiles.active的值,通常分别代表开发环境和测试环境。@Profile注解中配置的参数所代表的环境才能访问Swagger UI。
2)通过给Swagger配置类添加@ConditionalOnProperty注解实现,示例代码如下:
@Configuration
@EnableSwagger2
@ConditionalOnProperty (prefix="swagger2", value={"enable"}, havingValue="true")
public classSwaggerConfig{……}
在application- {spring.profiles.active}.yml(或.properties)中增加属性配置:
swagger2:
enable:true
true代表Swagger UI可访问,false代表Swagger UI被禁止访问。
[考点] Swagger
7. MyBatis实现一对一查询有几种方式?
MyBatis有两种方式可以实现一对一查询,都是通过association标签实现。
1)在resultMap中用association标签嵌套一对一关联查询的对象,然后在查询时通过关联查询将一对一对象的信息字段与对象自身的字段一起查询出来。实现如下:
<resultMap type="com.User" id="baseMap">
<id column="user_id" property="userId"/>
<result column="name" property="name"/>
<association property="address" JavaType=" com.Address">
<result column="address_id" property="addressId"/>
<result column="info" property="info"/>
</association>
</resultMap>
<select id="getUserList" resultMap="baseMap">
select a.user_id, a.name, b.address_id, b.info from t_user a, t_address b where a.address_id=c.address_id
</select>
2)通过association标签嵌套查询来实现一对一查询,具体实现如下:
<resultMap type="com.User" id="baseMap">
<id column="user_id" property="userId"/>
<result column="name" property="name"/>
<association property="address" JavaType="com.Address" column="address_id" select="getAddressById"/>
</resultMap>
<select id="getUserList" resultMap="baseMap">
select * from t_user
</select>
<select id="getAddressById" resultType="com.Address">
select address id addressId, info from t_address where address_id=#{addressId}
</select>
说明一下,这里是嵌套了子查询getAddressById,对应的是association标签的select属性,column是设定关联字段。
[考点] MyBatis
8. 按要求统计每年每月的信息。
表数据如下。
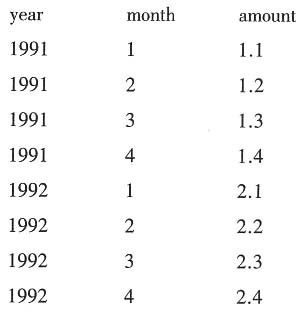
要求查出如下这样一个结果(与工资条非常类似,与学生的科目成绩也相似):

建表SQL语句为:
create table sales (id int auto_increment primary key, year varchar (10), month varchar (10),amountfloat (2,1));
此时如何用一条SQL统计每年每月的信息?
统计SQL为:
select sales.year,
(select t.amount fromsales t where t.month='1' and t.year=sales.year)'1',
(select t.amount fromsales t where t.month='1' and t.year=sales.year)'2',
(select t.amount fromsales t where t.month='1' and t.year=sales.year)'3',
(select t.amount fromsales t where t.month='1' and t.year=sales.year) as'4'
from sales group by year;
[考点] SQL语法与实战
9. Redis支持哪些数据类型?
Redis支持五种基本数据类型:String(字符串)、Hash(哈希)、List(列表)、Set(集合)及ZSet(Sorted Set有序集合)。还支持HyperLogLog、Geospatial、BitMap等数据结构,此外还有BloomFilter、RedisSearch、Redis-ML等。
HyperLogLog是用来做基数统计的算法,HyperLogLog的优点是,在输入元素的数量或者体积非常大时,计算基数所需的空间总是固定的、并且是很小的。HyperLogLog只会根据输入元素来计算基数,而不会储存输入元素本身。
Geospatial用于地理位置的存储和计算,Redis3.2版本开始提供此功能。
BitMap实际上不是特殊的存储结构,其本质上是二进制字符串,可以进行位操作,其经典应用场景之一是日活跃用户统计。
[考点] Redis
10. 如何理解XmlHttpRequest对象?
XmlHttpRequest是AJAX的核心对象,它是AJAX实现的关键——发送异步请求、接收响应及执行回调都是通过它来完成的。该对象在Internet Explorer 5中首次引入,所有现代的浏览器都支持XmlHttpRequest对象。它是一种支持异步请求的技术,JavaScript通过XmlHttpRequest可以向服务器提出请求并处理响应,而不阻塞用户。通过XmlHttpRequest对象,Web开发人员可以在页面加载后进行页面的局部更新,在网页的客户端和服务器端之间建立独立的连接通道。
从XmlHttpRequest调用返回的数据通常由后端数据库提供。除了XML之外,XmlHttpRequest还可用于获取其他格式的数据,例如JSON甚至纯文本。
[考点] AJAX与JavaScript
11. 什么是AJAX?
AJAX是Asynchronous JavaScript and XML的缩写。翻译成中文就是“异步JavaScript和XML”,是一种创建交互式网页应用的网页开发技术。AJAX可以使网页实现无跳转异步更新,就是在不重新加载整个网页的情况下,从服务器端获取数据并实现页面信息的全部或部分刷新。通过使用AJAX,可以获得良好的用户体验。
AJAX不是一门编程语言,它是一个使用已有标准的编程技术。
[考点] AJAX与JavaScript
12. 关于Tomcat的一些优化技巧。
提高JVM栈内存。
遇到Tomcat的内存溢出问题,通常情况下,产生这种问题的原因是Tomcat分配较少的内存给进程,通过修改配置参数Java_OPTS可以解决这个问题,配置参数在(Windows下的)bin/catalina.bat或(Linux下的)bin/catalina.sh文件中,具体参数配置示例如下:
setjava_OPTS=%Java_OPTS%-server-Xms1024m -Xmx1024m -XX:NewSize=512m -XX:MaxNewSize=512m-xx:PermSize=512m -XX:MaxPe rmSize=512m -XX:+DisableExplicitGC
-Xms -指定初始化时的内存。
-Xmx -指定最大内存。
增大这两个配置参数值后,重启Tomcat服务器便可生效。一般建议参数值为128M的倍数。
2)连接器最大线程数设置。
最大线程数指定Web请求负载的数量,Tomcat的默认值为150,在server.xml文件中配置。如果系统访问量大,Tomcat可能没有足够的线程来处理所有的请求,这时其他请求将进入等待状态,只有其他处理线程释放后才能被处理。在默认值不能满足系统要求时,可以通过调整连接器属性"maxThreads"完成设置。maxThreads的值,设置太大可能超出Tomcat的负载能力。不同的系统设置的最大值可以不同,可以根据实际情况来设置。如果超出负载能力,则需要部署集群。
3)开启浏览器的缓存。
开启浏览器的缓存,这样读取存放在Webapps文件夹里的静态内容会更快,提升访问性能。一般情况下HTTPs请求会比HTTP请求慢。但如果要求安全性,还是应该选择HTTPs。
4)利用缓存和压缩。
对于静态页面最好是能够缓存起来,这样就不必每次从磁盘上读取。可以采用Nginx作为缓存服务器,将图片、CSS、JS文件都进行缓存,可有效地减少对后端Tomcat的访问。
另外,为了能加快网络传输速度,开启gzip压缩也是必不可少的。但考虑到Tomcat已经需要处理很多东西了,所以把这个压缩的工作就交给前端的Nginx来完成。除了文本可以用gzip压缩,很多图片也可以用图像处理工具预先进行压缩,找到一个平衡点可以让画质损失很小而文件可以减小很多。
[考点] Web服务器
13. JSP有哪些基本动作?
JSP共有以下6种基本动作,见下表。
JSP基本动作

[考点] Java Web基础
14. Hibernate有哪三种实体状态?三种状态是如何转换的?
Hibernate实体有三种状态:临时态(Transiant)、持久态(Persistent)和游离态(Detached)。
1)临时状态(Transiant)。
临时状态的特征如下。
●不处于Session缓存中。
●数据库中没有对象记录,没有ID值。
实体如何进入临时状态。
●通过new语句刚创建一个对象时可进入临时状态。
●当调用Session的delete()方法从Session缓存中删除一个对象时可进入临时状态。
2)持久化状态( Persisted)。
持久化状态的特征如下。
●处于Session缓存中。
●持久化状态时对象在数据库中可能存有对象记录。
●Session在特定时刻会保持二者同步。
实体如何进入持久化状态。
●Session的save()把临时状态转为持久化状态。
●Session的load()、get()方法返回的对象进入持久化状态。
●Session的find()返回的list集合中存放的对象是持久化状态。
●Session的update()、saveOrupdate()使实体对象从游离状态转化为持久状态。
3)游离状态(Detached)。
游离状态的特征如下。
●不再位于Session缓存中。
●游离对象由持久化状态转变而来,数据库中可能还有对应记录。
实体如何从持久化状态进入游离状态。
●Session执行close()方法后,实体对象从持久化状态变成游离状态?
Session的evict()方法,从缓存中删除一个对象。可提高性能,但应当少用。
[考点] Hibernate与JPA
15. Spring Boot Actuator的一些常用功能与属性介绍。
Actuator的常用功能很多,这里选择常用的进行介绍。
1)开启和禁用单个端点。默认除shutdown外都是开启的,禁用所有端点前文已经介绍,禁用单个端点可以如此配置:
management.endpoint.health.enabled=false #关闭health端点
2)开放所有端点的Web访问。2.0以上版本默认只有health和info这两个端点是对外暴露的。开放所有端点的访问配置:
management.endpoints.Web.exposure.include='*' #yml中为'*'
3)开放其他单个或多个端点的Web访问配置:
management.endpoints.Web.exposure.include=["health"] #多个逗号分隔
需要注意的是,如果这里配置了单个或多个端点,则默认被替换,只有配置的端点才对外暴露。如果没有health,访问Actuator根目录时,Actuator后台会抛出异常,提示health是必须暴露的。
4)项目启动后Actuator默认访问地址是Http: //localhost: 8080/actuator。如需要修改,可如下设置:
management.endpoints.Web.base-path=/myactuator #/myactuator为自定义地址
5)修改端点的默认访问地址。这里以health为例:
management.endpoints.Web.path-mapping.health=myhealth
就可以用/actuator/myhealth查看health信息了,这时默认地址/actuator/health失效,不能访问。
6)Spring Boot Actuator内置了很多端点,是支持扩展的,可以自定义端点。
[考点] Spring Boot
16. 什么是Cookie攻击?如何防范Cookie攻击?
Cookie中通常会保存用户的一些敏感信息,如用户名和登录密码等信息,虽然Cookie值已加密处理,但是当攻击者窃取到Cookie后无须破解,只要把Cookie信息向服务器提交并通过验证后,他们就可以冒充受害人登录,这就是Cookie攻击。
那么如何防止Cookie攻击呢?推荐的做法是登录验证通过将当前Cookie的ID保存在Session中,每次访问时验证一下Cookie的ID是否与Session中保存的Cookie的ID一致,如果不一致,就可以确定是非法访问了。
[考点] 软件安全知识
17. 什么是MongoDB的索引?如何创建查看索引?写操作如何影响索引?
MongoDB的索引和关系型数据库索引的作用一样,都是为了能高效地执行查询。没有索引,MongoDB将扫描查询整个集合中的所有文档,这种扫描效率很低,需要处理大量数据。索引是一种特殊的数据结构,将一小块数据集保存为容易遍历的形式。索引能够存储某种特殊字段或字段集的值,并按照索引指定的方式将字段值进行排序。确定要索引的字段,应当根据各种因素来决定,包括选择性、对多种查询形状的支持,以及索引的大小。
在集合上创建索引,使用db.collection.createIndex()方法。
列出集合的索引,使用db.collection.getIndexes()方法。
分析MongoDB如何处理查询,请使用explain()方法。
如需要查看索引的大小,在db.collection.stats()方法返回值中包括一个indexSizes文档,该文档为集合中的每个索引提供了大小信息。查看索引大小信息,可以根据其大小,判断索引是否适合RAM。当服务器具有足够的RAM用于索引和其余工作集时,索引就适合RAM。当索引太大而无法放入RAM时,MongoDB必须从磁盘读取索引,这比从RAM读取要慢得多。在某些情况下,索引不必完全适合RAM。
和关系型数据库一样,写操作对索引的影响体现在写操作可能需要更新索引,从而影响性能。如果写操作修改了索引字段,则MongoDB将更新所有将修改后的字段作为键的索引。
因此,如果应用程序对MongoDB有大量写操作,则索引可能会影响性能。
[考点] MongoDB
18. JDBC是如何操作事务的?
JDBC通过Connection组件提供了事务处理的相关方法。默认为自动提交事务,通过调用Connection组件的setAutoCommit(false)方法可以设置事务手动提交,当事务完成后用commit()显式提交事务。如果在事务处理过程中发生异常则通过rollback()进行事务回滚。从JDBC3.0开始还引入了Savepoint(保存点)的概念,允许通过代码设置保存点并让事务回滚到指定的保存点。
[考点] JDBC相关
19. 什么是缓存雪崩?如何预防缓存雪崩?
如果缓存集中在一段时间内失效,也就是通常所说的热点数据集中失效(一般都会给缓存设定一个失效时间,过了失效时间后,该数据库会被缓存直接删除,从而一定程度上保证数据的实时性),发生大量的缓存穿透,造成大量的查询要查询数据库,这就造成了缓存雪崩,可能会导致数据库崩溃。
下面推荐几个缓存雪崩的解决办法。
●在缓存失效后,通过加锁或者队列来控制读数据库重建缓存的线程数量。例如,同一时刻只允许一个线程查询数据和重建缓存,其他重建缓存的线程此时在等待状态。
●可以通过缓存reload机制,预先去更新缓存,在即将发生大并发访问前手动触发加载缓存。
●不同的Key,设置不同的过期时间,让缓存失效的时间点尽量均匀。例如,可以在原有的失效时间基础上增加一个随机值,如1~5min随机,这样每一个缓存的过期时间的重复率就会降低,就会大大降低缓存集体失效的概率。
●做二级缓存,或者双缓存策略。A1为原始缓存,A2为备份缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。
[考点] NoSQL与缓存综合
20. WebService、RPC、RMI、Restful的区别?
RPC(Remote Procedure Call),远程过程调用,使用C/S方式,支持像调用本地服务(方法)一样调用服务器的服务(方法)。RPC不支持对象的概念,传送到RPC服务的消息由外部数据语言表示(External Data Representation,XDR)。这种语言抽象了字节序类和数据类型结构之间的差异。只有由XDR定义的数据类型才能被传递。优点是跨语言、跨平台,缺点是不支持对象,无法在编译器检查错误,只能在运行期检查。
RMI被认为是面向对象方式的Java RPC,允许方法返回Java对象及基本数据类型。优点是强类型,编译期可检查错误;缺点是只能基于Java语言,客户机与服务器紧耦合。
WebService也是是一种跨编程语言、跨操作系统平台的远程调用技术。传统的WebService是基于SOAP实现的,以HTTP+XML方式传输数据。以WSDL(Web Sen,ices Description Language),即Web服务描述语言描述服务,以UDDI(Universal Description,Discovery and Integration)即通用描述、发现与集成服务)注册、发布、搜索服务。WebService的优点也是跨语言跨平台。缺点是性能相对较低,在易用性与学习成本方面不如RMI等。
表述性状态传递(Representational State Transfer,REST),以URI对网络资源进行唯一标识,响应端根据请求端的不同需求,通过无状态通信,对其请求的资源进行表述。基于REST构建的API就是Restful风格,REST使用HTTP+URI+XMUJSON的技术来实现其API要求的架构风格。Restful是目前最流行的WebService实现方式,相比传统WebService,它的实现更简洁,开发调用都更简单方便。也更轻量级、效率更高。
[考点] 网络编程与远程调用



 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题