某CPU的主振频率为100 MHz,平均每个机器周期包含4个主振周期。各类指令的平均机器周期数和使用频度如表2.9所示,则该计算机系统的速度为平均约 5 兆指令/秒。若某项事务处理工作所要执行的机器指令数是控制程序(以访内、比较与转移等其他指令为主)220000条指令和业务程序(以包括乘除在内的算术逻辑运算为主)90000条指令,且指令使用频度基本如表2.9所示,则该计算机系统的事务处理能力约为 6 项/秒。若其他条件不变,仅提高主振频率至150 MHz,则此时该计算机速度为平均约 7 兆指令/秒,对上述事务的处理能力约为 8 项/秒。若主频仍为100 MHz,但由于采用了流水线和专用硬件等措施,使各类指令的每条指令平均机器周期数都变为1.25,则此时计算机的速度平均约 9 兆指令/秒。
表2.9 各类指令的平均机器周期数和使用频度 指令类别 | 平均机器周期数/指令 | 使用频度 |
访内存 | 2.5 | 25% |
一般算术逻辑运算 | 1.25 | 40% |
比较与转移等 | 1.5 | 25% |
乘除 | 15 | 5% |
其他 | 5 | 5% |
5. A.1 B.5 C.10 D.15 E.20 F.33.3 G.50 H.66.7 I.100 J.200
A B C D E F G H I J
C
(5-9)指令平均占用总线周期数=2.5×25%+1.25×40%+1.5×25%+15×5%+5×5%=2.5s每秒指令数=时钟频率/每个总线周期包括的时钟周期数/指令平均占用总线周期数 =100M/4/2.5 s=10M
计算机系统的事务处理能力即为单位时间内执行程序的能力。
由题中列出的使用频度我们可以得出如表2.12所示的结论。
表2.12 指令种类、指令条数及平均周期
指令种类 |
访存指令 |
比较转移指令 |
其他指令 |
算术运算指令 |
乘除指令 |
指令条数 |
约为100000条 |
约为100000条 |
约为20000条 |
约为80000条 |
约为10000条 |
平均周期 |
2.5 |
1.5 |
5 |
1.25 |
15 |
项事务处理共需机器周期个数=10
5×2.5+10
5×1.5+0.2×10
5×5+0.8×10
5×1.25+0.1×10
5×15 =750000个
因为主振频率为100MHz,平均每个机器周期包含4个主振周期,所以每秒有100M/4= 25M个机器周期。
一项事务所需时间为750000/25000000≈0.03s,即每秒处理事务I/0.03s=33.3项。
表2.10 指令的使用频度 Ⅰ1 | Ⅰ2 | Ⅰ3 | Ⅰ4 | Ⅰ5 | Ⅰ6 | Ⅰ7 | Ⅰ8 | Ⅰ9 | Ⅰ10 | Ⅰ11 | Ⅰ12 | Ⅰ13 | Ⅰ14 |
0.15 | 0.15 | 0.14 | 0.13 | 0.12 | 0.11 | 0.04 | 0.04 | 0.03 | 0.03 | 0.02 | 0.02 | 0.01 | 0.01 |
10.
A B C D
B
(10-11)使用等长编码方式,如果指令编码长度是3位,它能够表示2
3=8条指令,而2
4=16>14,所以至少要4位编码长度才能将这14条指令编码。
哈夫曼编码技术是一种比较常用的变长编码方法,它采用的是一种优化静态编码方法,由该算法产生的二叉树具有最小的加权长之和∑W
iL
i,其中,W
j是哈大曼树中第j个叶节点的权值,L
i为该叶节点到树根的距离。将题目转换为哈夫曼编码树,然后对其进行调整,如图2.23所示。
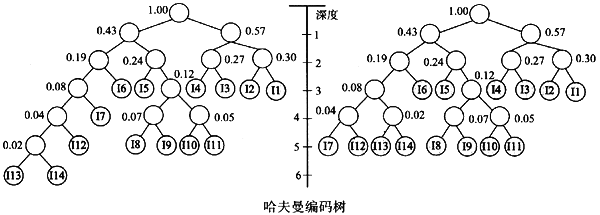
这样,树中的所有节点的深度都为3或5,所以我们可以按照码长乘以频度,再累加的方法来计算平均码长:
(0.15+0.15+0.14+0.1340.12+0.11)×3+(0.04+0.04+0.03+0.03+0.02+0.02+0.0140.01)×5=3.4
表2.11 处理机的存取周期 | TIC/nx | TIM/ms |
X | 40 | 1 |
Y | 100 | 0.9 |
Z | 120 | 0.8 |
若某段程序所需指令或数据在Cache中取到的概率为P=0.5,则处理机X的存储器平均存取周期为 50 ms。假定指令执行时间与存储器的平均存取周期成正比,此时三个处理机执行该段程序由快到慢的顺序为 51 。
若P=0.65,则顺序为 52 。
若P=0.8,则顺序为 53 。
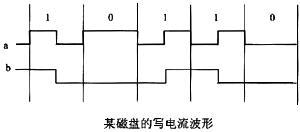
若P=0.85,则顺序为 54 。 在多级存储系统中,Cache处在CPU和主存之间,解决 55 问题。若Cache和主存的存取时间分别为T1和T2,Cache的命中率为H,则该计算机实际存取时间为 56 。当CPU向存储器执行读操作时,首先访问Cache,若命中,则从Cache中取出指令或数据,否则从主存中取出,送 57 :当CPU向存储器执行写操作时,为了使Cache的内容和主存的内容保持一致,若采用 58 法,则同时写入Cache和主存。由于Cache容量比主存容量小,因此当Cache满时,执行把主存信息向Cache写入,就要淘汰Cache中已有的信息,为了提高Cache的命中率,采用一种 59 替换算法。 若磁盘的写电流波形如图2-22所示。图中波形a的记录方式是 61 ;波形b的记录方式是 62 。 硬磁盘存储器的道存储密度是指 63 ,而不同磁道上的位密度是 64 。 SCSI是一种通用的系统级标准输入/输出接口,其中 65 标准的数据宽度16位,数据传送率达20MB/s。大容量的辅助存储器常采用RAID磁盘阵列。RAID的工业标准共有六级。其中, 66 是镜像磁盘阵列,具有最高的安全性; 67 是无独立校验盘的奇偶校验码磁盘阵列: 68 是采用纠错汉明码的磁盘阵列; 69 则是既无冗余也无校验的磁盘阵列,它采用了数据分块技术,具有最高的I/O性能和磁盘空间利用率,比较容易管理,但没有容错能力。 直接存储器访问(DMA)是一种快速传递大量数据常用的技术。其工作过程大致如下:
(1)向CPU申请DMA传送;
(2)获得CPU允许后,DMA控制器接管 73 的控制权;
(3)在DMA控制器的控制下,在存储器和 74 之间直接进行数据传送,在传送过程中不需要 75 的参与。开始时需提供要传送数据的 76 和 77 。
(4)传送结束后,向CPU返回DMA操作完成信号。 



 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题