一、单项选择题3. 设栈S和队列Q的初始状态为空,元素e
1、e
2、e
3、e
4、e
5和e
6依次通过栈S,一个元素出栈后即进入队列Q,若6个元素出列的顺序是e
2、e
3、e
4、e
5、e
6、e
1,则栈S的容量至少应该是
A B C D
5. 已知用某种排序方法对关键字序列(51,35,93,24,13,68,56,42,77)进行排序时,前两趟排序的结果为
(35,51,24,13,68,56,42,77,93)
(35,24,13,51,56,42,68,77,93)
所采用的排序方法是
A B C D
B
[解析] 由题目中第一趟排序的结果是将所有关键字中最大的关键字(97)放在了序列最后,第二趟排序的结果是将除97以外的所有关键字中最大的关键字放在了序列中倒数第二个位置,可知此排序方法为冒泡排序。
二、填空题1. 设线性表L=(a
1,a
2,…,a
n)(n>2),表中元素按值的递增顺序排列。对一个给定的值k,分别用顺序检索和二分法检索查找与k相等的元素,比较次数分别为s和b,若检索不成功,则s和b的数量关系是______。
2. 由权值为1,2,3,4,5,6的六个叶子结点构成一棵哈夫曼树,则带权的路径的长度为______。
3. 在二叉排序树中,其左子树中任何一个结点的关键字一定______其右子树的各结点的关键字。
4. 若序列中关键字相同的记录在排序前后的相对次序不变,则称该排序算法是______的。
5. 对无向图,其邻接矩阵是一个关于______对称的矩阵。
6. 和二分查找相比,顺序查找的优点是除了不要求表中数据元素有序之外,对______结构也无特殊要求。
7. 含n个顶点的无向连通图中至少含有______条边。
8. 对表长为9000的索引顺序表进行分块查找,假设每一块的长度均为15,且以顺序查找确定块,则在各记录的查找概率均相等的情况下,其查找成功的平均查找长度为______。
9. 查找表中主关键字指的是______,次关键字指的是______。
能惟一标识数据元素的数据项 不能惟一标识数据元素的数据项
10. 设二维数组A[10··20,5··10]按行优先存储·,每个元素占4个存储单元,A[10,5]的存储地址是1000,则A[15,10]的存储地址是______。
三、解答题1. 已知连通图如下:
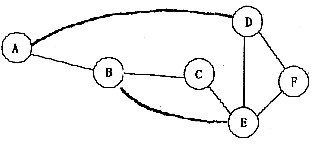
分别以邻接矩阵的邻接表实现存储,试给出该图的邻接矩阵和邻接表,若从顶点B出发对该图进行遍历,分别给出一个按深度优先搜索和广度优先搜索的顶点序列。
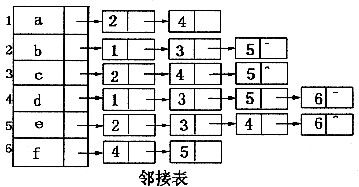

深度优先搜索顶点序列为:
b a d f e c
广度优先搜索顶点序列为:
b a c e d f
2. 图的邻接表的类型定义如下所示:
#define MaxVertexNum 50
typedef struct node{
int adjvex;
struct node*next;
}EdgeNode;
typedef struct{
VertexType vertex;
EdgeNode*firstedge;
}VertexNode;
typedef VertexNode A djList[MaxVertexNum];
typedef struct{
AdjList adjiist;
int n,e;
}ALGraph;
为便于删除和插入图的顶点的操作,可将邻接表的表头向量定义为链式结构,两种定义的存储表示实例如下图所示,请写出重新定义的类型说明。
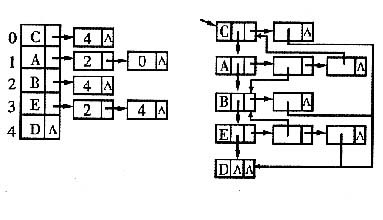
typeclef struct ArcNode{
VNode*adjvex; //该弧所指向的顶点的位置
struct ArcNode*nextarc; //指向下一条弧的指针
}ArcNode;
typedef struct VNode{
VertexType data; //顶点信息
struct VNode*nextVertex; //指向下一个顶点的指针
ArcNode*firstarc; //指向第一条依附该顶点的弧
}VNode.*AdjList;
typedef struct{
AdjList adjList;
int n,e;
}ALGraph;
3. 对于如图所示的二叉树,请画出其顺序存储结构图。
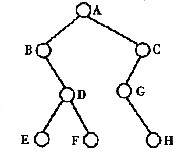
二叉树的顺序存储就是将二叉树的结点按编号存在向量B[0,n]中,其中B[0]用来存放结点T数,如果树中某些编号对应的结点不存在,则对应存储空间为“空”,根据上述规则,我们得到:

4. 假设有一个长度为n的有序序列,在进行查找时,可以借助二叉树来进行,请结合二叉树的性质来分析二分查找的最坏性能和平均性能。
假设判定树的内部结点的总数为n=2
h-1。则判定树是深度为h=lg(n+1)的满二叉树,树中第k层上的结点的个数为2
h-1,查找它们所需要比较的次数是k。则在等概率下,二分查找成功时的平均查找长度为:
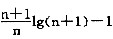
,如果n很大,则可以用如下近似公式:lg(n+1)-1,作为二分查找成功时的平均查找长度。二分查找在查找失败时所需要比较的关键字的个数不超过判定树的深度,在最坏情况下查找成功的比较次数也不超过判定树的深度。因为判定树中度数小于2的结点只可能在最下面的两层上,所以n个结点的判定树的深度和n个结点的完全二叉树的深度相同,即为lg(n+1),所以,二分查找的最坏性能和平均性能十分接近。
四、算法阅读题1. 请将下面的程序改成递归的过程。
voide ditui(int n)
{int i;
i=n;
while(i>1)
prinft(i--);
}
此递推过程可以改写成如下递归过程:
voide dkui(int j)
{if(i>1)
{prind(j);
digui(j-1);
}
}
2. 求下面算法中变量count的值:(假设n为2的乘幂,并且n>2)
int Time
{int n
count=0;x=2;
while(x<n/2)
{x
*=2;count++;
}
return(count)
}
typedef struct Node{
int id; /*学号*/
int score; /*成绩*/
srruct Node*next;
}LNode,*LinkList;
阅读算法f31,并回答问题:
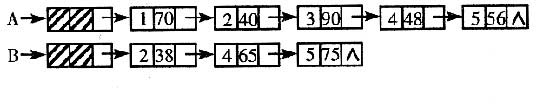
(1)设结点结构为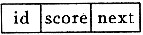 ,成绩链表A和B如图所示,画出执行算法f31(A,B)后A所指的链表;
,成绩链表A和B如图所示,画出执行算法f31(A,B)后A所指的链表;
(2)简述算法f31的功能。
void f31(LinkList A,LinkList B)
{ LinkList p,q;
p=A—>next;
q=B—>next;
while(p&&q)
{ if(p—>id p=p—>next;
else if(p—>id>q—>id)
q=q—>next;
else
{ if(p—>score<60)
if(q—>score<60)
p—>score=q—>score;
else p—>score=60;
p=p—>next;
q=q—>next;
}
}
}4.
对于表A中成绩低于60的学生,如果在表B中也有成绩记录,则将表A中的成绩修改为其在表B中的成绩;但若其在表B中的成绩高于60分,则只改为60分。
五、算法设计题1. 设计一个双向起泡排序算法,即在排序过程中交替改变扫描方向。
可通过设置一个标志位进行区分的方式来进行交替扫描,算法描述如下:
Alterbubblesort(r) /*交替扫描法起泡排序*/
Reetype R[];
{int i,j,temp,flag; /*设置扫描标志flag*/
flag=True;
i=0;
while(flag) /*开始扫描*/
{ flag=False;
for(j=n=i,j<i,j--)
{if(R[j],key<R[j-1],key)
{flag=True;
temp=R[j];
R[j]=R[j-1];
R[j-1]=temp;
}
}
for(j=l;j<n-1;j++)
{if(R[j].key>R[j+1].key)
{flag=True;
temp=R[j];
R[j]=R[i+1];
R[j-1]=temp;
}
}
i++; /*往右扫描*/
}
} /*AIterbubblesort*/




 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题