二、简答题(每题10分)1. 什么是统计量?有何意义?
(1)设X1,X2…,Xn是从总体X中抽取的容量为n的一个样本,如果由此样本构造一个函数T(X1,X2,…,Xn),不依赖于任何未知参数,则称函数T(X1,X2,…,Xn)是一个统计量。
(2)在实际应用中,当从某总体中抽取一个样本后,并不能直接用它去对总体的有关性质和特征进行推断,这是因为样本虽然是从总体中获取的代表,含有总体性质的信息,但仍较分散。为了使统计推断成为可能,首先必须把我们所关心的分散在样本中的信息集中起来,针对不同的研究目的,构造不同的样本函数。
2. 简述不相关和独立的定义、联系和区别。
对于随机变量X与Y,若Var(X)>0,Var(Y)>0,则称

为X与Y的相关系数,记为ρ或ρ
XY。若ρ
XY=0,则称随机变量X与Y不相关。对于随机变量X与Y,若P{X≤x,Y≤y}=P{X≤x}P{Y≤y}成立,则称随机变量X与Y是相互独立的。
两者的联系:独立性和不相关性都是随机变量间联系“薄弱”的一种反映。若X与Y独立,则X与Y不相关。在二维正态分布中,不相关与独立是等价的。
两者的区别:两个随机变量相互独立与不相关是两个不同的概念,不相关只说明两个随机变量之间没有线性关系,但这时的X与Y可能有某种别的函数关系;而相互独立说明两个随机变量之间没有任何关系,既没有线性关系,也没有其他关系。
3. 什么是概率抽样,其特点是什么?列举5种概率抽样组织方式。
概率抽样也称随机抽样,是指遵循随机原则进行的抽样,总体中每个单位都有一定的机会被选入样本。
概率抽样的特点:概率抽样是依据随机原则抽选样本,样本统计量的理论分布是存在的,因此可以根据调查的结果对总体的有关参数进行估计,计算估计误差,得到总体参数的置信区间,并且在进行抽样设计时,对估计的精度提出要求,计算为满足特定精度要求所要的样本量。
概率抽样组织方式有以下几种:
(1)简单随机抽样;
(2)分层抽样;
(3)整群抽样;
(4)系统抽样;
(5)多阶段抽样。
三、计算题(共80分,每题10-12分)1. 一零件的缺陷数服从参数为λ的泊松分布,λ有2种可能取值,P{λ=1}=0.8,P{λ=2}=0.2,现从中随机抽取2个零件,其缺陷数分别为0和1。
求出现上述抽样情况的概率。
解:设事件A=“随机抽取2个零件,其缺陷数分别为0和1”。由题意,λ有2种可能取值,
P{λ=1}=0.8,P{λ=2}=0.2,
则

2. 掷一枚骰子60次,出现情况如下:
问:这枚骰子是否均匀

解:原假设与备择假设分别为
H
0:这枚骰子是均匀的;
H
1:这枚骰子是不均匀的。
根据假设情况,骰子出现每一点数的概率为1/6,计算期望频数如下。

在α=0.05下,

落入接受域,不拒绝原假设,即认为骰子是均匀的。
3. 假设新冠感染率为0.01,问:10人一组进行检测为何能提高检测效率?
解:新冠感染率为0.01,假设其检测为阳性的概率即为0.01,以10人一组进行检测,设组内每人检测的次数为X,则X的分布律为
则X的数学期望为

即每个人平均的检验次数为0.196次,小于1次,由此可以认为10人一组进行检测可以降低平均检测量,从而提高检测效率。
4. 在90%的把握下,比例p与p
0之间的差异不超过5%,问最少需要多少样本量?
解:边际误差(估计误差)

则

故应抽取的样本量为n=1068。
[考点] 本题主要考查有关比例区间估计的样本量计算,只要将样本量计算公式牢记即可。
[解析] 样题:在95%的置信水平下,以0.03的边际误差构造总体比例的置信区间时,应抽取多少样本量?
5. 不同学院学生周末学习时间如下表所示:
| 物理学院 | 8.1 | 8.3 | 8.0 | 8.5 | 7.9 | 8.6 |
| 化学学院 | 7.6 | | | | | |
| 数学学院 | 8.2 | | | | | |
| 生物学院 | 7.8 | | | | | |
不同学生周末学习时间是否有差异。
解:作出假设:
H
0:μ
1=μ
2=μ
3=μ
4;
H
1:μ
1,μ
2,μ
3,μ
4不全相等。
由题得n
1=n
2=n
3=n
4=5,n=20,则
T
·1=51,T
·2=30,
T·3=-8,T
·4=-43,T=30,
故
SST=2015,SSA=1037.8,SSE=977.2,
则方差分析表为
| 差异源
|
SS
|
df
|
MS
|
F
|
| 组间
|
1037.8
|
3
|
345.9
|
5.66
|
| 组内
|
977.2
|
16
|
61.08
|
|
| 总计
|
2015
|
19
|
|
|
故

拒绝原假设,即认为4种产品有显著差异。
[考点] 本题主要考查单因素方差分析,熟练掌握方差分析的原理,SST,SSA与SSE的计算公式即可。
[解析] 样题:四个商城生产四种产品,每家抽取了5件产品,记为A
1,A
2,A
3,A
4,A
5,数据如下表所示:
|
|
A1
|
A2
|
A3
|
A4
|
A5
|
| 1
|
22
|
24
|
0
|
1
|
4
|
| 2
|
7
|
5
|
4
|
12
|
2
|
| 3
|
-4
|
-5
|
-4
|
14
|
-9
|
| 4
|
-11
|
-4
|
-12
|
-9
|
-7
|
分析不同商城的产品是否有显著差异。
(注:F
0.95(3,16)=3.24,t
0.975(16)=2.1788)
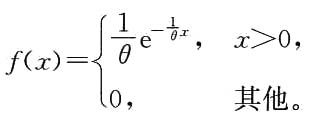
6. 求X的分布函数F(x).
当x<0时,
F(x)=P{X≤x}=0;
当x≥0时,

所以分布函数为

8. H
0:θ≤θ
0,H
1:θ>θ
0,建立统计量,并给出拒绝域。
由密度函数可以确定X服从指数分布,则构建检验统计量为

由题中假设可以确定为右单侧检验,给定显著性水平为α,拒绝域为

其中

9. 已知

的值。
(1)

(2)

(3)

(4)给定x
0求相应

的估计值,并给出预测区间。
缺
[考点] 本题主要考查关于一元线性回归的参数估计,统计量的分布以及预测的问题。






 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题