一、单项选择题5. 设X
1,X
2,X
3,X
4是来自正态总体N(0,1)的简单随机样本,如果Y=a(X
1+X
2)
2+b(2X
4-X
3)
2~χ
2(2),则常数(a,b)等于______。
A.(1/2,1/5)
B.

C.(1/2,1/3)
D.

A B C D
四、简答题(每小题5分,共30分)1. 什么是回答误差?请给出导致回答误差的三种主要原因。
回答误差是指被调查者在接受调查时给出的回答与真实情况不符。导致回答误差的原因有多种,主要有理解误差,记忆误差和有意识误差。
(1)理解误差。
不同的被调查者对调查问题的理解不同,每个人都按自己的理解回答,大家的标准不一致,由此造成理解误差。
(2)记忆误差。
有时,调查的问题是关于一段时期内的现象或事实,需要被调查者回忆。需要回忆的时间间隔越久,回忆的数据可能就越不准确。
(3)有意识误差。
当调查的问题比较敏感,被调查者不愿意回答,迫于各种原因又必须回答时,可能就会提供一个不真实的数字,由此造成有意识误差。
2. 一枚硬币连续抛10次,8次都是正面朝上,利用假设检验的方式推测硬币不均匀是否合理?
若硬币为均匀的,则出现正面与出现反面的概率应相等,均为0.5。根据题意建立原假设与备择假设为
H
0:p=0.5,H
1:p≠0.5。
由题意得,n=10,x
0=8,可计算检验的p值为

因此不拒绝原假设,认为硬币不均匀不合理。
3. 在单侧假设检验H
0:μ≥μ
0,H
1:μ<μ
0以及H
0:μ≤μ
0,H
1:μ>μ
0中,有可能出现两个检验都不拒绝H
0的现象,这种现象矛盾吗?请说明原因。
不矛盾。
不拒绝H0并不代表H0一定是正确的,只能说明目前没有充分的理由证明H0是错误的。同时,得到不拒绝H0的结论有可能犯第二类错误。
以假设正态总体,方差已知,α=0.05为例:
针对假设为H0:μ≥μ0,H1:μ<μ0的问题,拒绝域为
W={u<1.645}。
针对假设为H0:μ≤μ0,H1:μ>μ0的问题,拒绝域为
W={u>1.645}。
以上两个假设的接受域存在交集(-1.645,1.645),而用样本计算的检验统计量值可能处于-1.645~1.645之间,此时对于以上两个假设均落入接受域,均不拒绝原假设,并不存在矛盾。
4. 在多元线性回归中,为什么在线性关系的F检验之后,通常还要对每个回归系数进行是否为0的t检验?
在多元线性回归中,线性关系检验(回归方程的检验)主要是检验因变量同多个自变量的线性关系是否显著,在k个自变量中,只要有一个自变量与因变量的线性关系显著,F检验就能通过,但这不一定意味着每个自变量与因变量的关系都显著。
回归系数检验则是对每个回归系数分别进行单独的检验,它主要用于检验每个自变量对因变量的影响是否显著。如果某个自变量没有通过检验,就意味着这个自变量对因变量的影响不显著,也就没有必要将这个自变量放进回归模型中了。另外,通过该步骤还可以初步判断自变量间是否存在多重共线性,当某些重要的自变量的回归系数t检验不通过而同时整个回归方程的线性关系检验又能通过时,则通常预示着自变量间存在多重共线性。
5. 如果一个时间序列存在趋势但是不存在季节性,请给出合理的预测方法。
当时间序列存在趋势但是不存在季节性时,主要的预测方法有线性趋势预测,非线性趋势预测和白回归模型预测等,具体采用哪种预测方法需要判断是线性趋势还是非线性趋势。
(1)通过时间序列图观察序列呈现的是线性趋势还是非线性趋势。如果明确是线性趋势则可以采取线性趋势预测,并采用最小二乘法拟合趋势方程。如果明确其为非线性趋势,则采用非线性方程进行描述,对于曲线方程中的参数,可采用线性化手段将其化为线性的形式,再按线性回归求得曲线方程。
(2)如果通过时间序列图观察无法明确区分序列呈现的是线性趋势还是非线性趋势,则可拟合多个方程,通过拟合优度或者均方误差来对比哪种曲线方程更优。
6. 在价格指数的编制中,为什么通常使用加权平均指数而非加权综合指数?
加权综合指数和加权平均指数虽然在形式上是相同的,但本质上还是有区别的,主要表现在是全面资料还是样本资料。如果是全面资料,可以采用加权综合指数,计算生产量指数一般属于这种情况,因为生产量指数要包含所有产品的生产情况;而计算价格指数时是无法得到全面资料的,因为市场商品的项目成千上万,做不到全面统计,只能采取选种方法,挑选代表规格品,在这种背景下,若采用加权综合指数,其结果就是仅仅计算r代表规格品的价格变化。价格指数要反映市场所有商品价格的变化,代表规格品是样本,其中的每一项都代表一类商品,每一项代表规格品要有自己的权数。在加权平均指数中,权数的本质是


其实就是用代表规格品所代表的那一类商品的销售额在全部销售额中的比重作为权数。在这样的背景下计算指数,只能采取加权平均指数方法。所以,加权平均指数方法主要用于价格指数的计算。
五、计算题(每小题6分,共30分)1. 设有n个袋子,每个袋子中装有a只黑球和b只白球,从第一个袋中取出一球放入第二袋中,然后从第二个袋中取出一球放入第三袋中,如此下去,问从最后一个袋中取出一球为黑球的概率是多少?
解:记A
i=“从第i个口袋中取出的是黑球”,P(A
i)=p
i,i=1,2,…,n。
由题意可得

则全概率公式为

由归纳法可得

因此
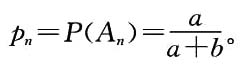
2. 假设总体X的分布为
现从此总体中抽取简单随机样本X
1,X
2,X
3,求样本中位数的概率分布。
解:根据题意可得,从中取出容量为3的样本,其一切可能取值有4
3=64(种),中位数可以取到0,1,3,5,根据X的分布列,记样本中位数为X
(2)。
X
(2)=0时,样本取值情况为(1)三个样本均取0;(2)两个样本取到0,另一个样本取到1,3,5中任意一个,

同理,X
(2)=5时,样本取值情况为(1)三个样本均取5;(2)两个样本取到5,另一个样本取到0,1,3中任意一个,

X
(2) =1时,样本取值情况为(1)一个样本取到1,其余两个样本一个取到0,另一个取到3,5;
(2)两个样本取到1,另一个样本取到0,3,5中任意一个;(3)三个样本均取到1,
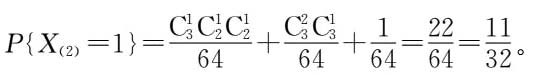
同理X
(2)=3时,样本取值情况为(1)一个样本取到3,其余两个样本一个取到5,另一个取到0,1;
(2)两个样本取到3,另一个样本取到0,1,5中任意一个;(3)三个样本均取到3,

则样本中位数的概率分布列为
3. 为适应市场需求,保险公司新推出一项保险业务,综合分析显示该业务每份保单的年赔付金额X服从参数为1/500的指数分布,其密度函数为

请问参保人数为900时,为使得保险公司在该项业务上有95%的把握盈利,每份保单的售价应该定为多少?(z
0.025=1.96,z
0.05=1.65)
解:由题意可得,每份保单的年赔付金额X的数学期望与方差为
E(X)=500,
D(X)=250000。
设总赔付金额为Y,则

根据中心极限定理有Y~N(900×500,900×250000),设每份保单的售价为a,总售价为900a,则保险公司在该项业务上有95%的把握盈利,即

每份保单的售价应该定为527.5。
4. 考虑无截距项的一元线性回归模型y=βx
i+ε
i,i=1,2,…n。其中y是因变量,x是自变量,β是影响系数,ε
i是扰动项.ε
i~N(0,σ
2)。请求β的最小乘估计量

的方差

5. 已知某个经济变量从2010年至2015年的观测值分别是100、105、110、99、104、109,如果利用指数平滑法进行预测,目,以均方误差来衡量测量误差的大小,请问平滑系数α=0.3和α=0.5哪个更好一些?给出计算过程。
解:指数平滑公式为F
t+1=αY
t+(1-α)F
t,平滑系数为0.3时,F
t+1=0.3Y
t+0.7F
t,
F
2011=0.3Y
2010+0.7F
2010=0.3Y
2010+0.7Y
2010=100,
F
2012=0.3Y
2011+0.7F
2011=0.3×105+0.7×100=101.5,
F
2013=0.3Y
2012+0.7F
2012=0.3×110+0.7×101.5=104.05,
F
2014=0.3Y
2013+0.7F
2013=0.3×99+0.7×104.05=102.535,
F
2015=0.3Y
2014+0.7F
2014=0.3×104+0.7×102.535=102.9745,
F
2016=0.3Y
2015+0.7F
2015=0.3×109+0.7×102.9745=104.78215。
平滑系数为0.5时,F
t+1=0.5Y
t+0.5F
t,同理分别得到预测值如下表:
| 年份
|
Y
|
F(α=0.3)
|
误差平方(α=0.3)
|
F(α=0.5)
|
误差平方(α=0.5)
|
| 2010
|
100
|
—
|
—
|
—
|
—
|
| 2011
|
105
|
100
|
25
|
100
|
25
|
| 2012
|
110
|
101.5
|
72.25
|
102.5
|
56.25
|
| 2013
|
99
|
104.05
|
25.5025
|
106.25
|
52.5625
|
| 2014
|
104
|
102.535
|
2.146225
|
102.625
|
1.890625
|
| 2015
|
109
|
102.9745
|
36.30665
|
103.3125
|
32.34766
|
| 2016
|
—
|
104.78215
|
|
106.15625
|
|
当平滑系数为0.3时,

平滑系数为0.5时,

因此平滑系数为0.3时的预测效果更好。
六、综合题(每小题10分,共30分)1. 已知一枚硬币抛出正面的概率为p,连续抛这枚硬币直到正反面都出现为止。请问当p为多少时平均抛掷次数最少?
解:设X表示“抛出硬币的次数”,直到正反面都出现时一共抛k次,则

由数学期望式子可以确定p(1-p)越大,平均抛掷次数越少,当p=0.5时,p(1-p)=0.25达到最大,因此当p=0.5时平均抛掷次数最少。
2. 在0.05的显著性水平下,检验2020年A地区具有研发投入的企业占比是否比2010年有了显著提高?
由题意可得,要检验具有研发投入的企业占比是否显著提高,可判断为右单侧检验,设置原假设与备择假设为
H
0:π≤10%,H
1:π>10%。
构造检验统计量为

α=0.05,z
0.05=1.65,z>z
0.05,落入拒绝域,拒绝原假设,认为2020年A地区具有研发投入的企业占比比2010年有显著提高。
3. 2020年从B地区中随机抽取400家企业,其中具有研发投入的企业65家,在0.05的显著性水平下,检验2020年A地区与B地区具有研发投入的企业占比是否有显著差异?
解:由题意可得,为双侧检验,设置原假设与备择假设为

构造检验统计量为

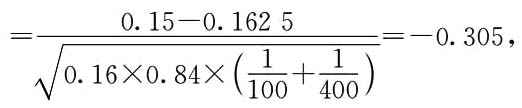
α=0.05,z
0.025=1.96,|z|<z
0.025,落入接受域,不拒绝原假设,故没有理由认为2020年A地区与B地区具有研发投入的企业占比有显著差异。
4. 以PM
2.5年平均浓度将城市归为以下三类:低污染城市(X
1<10μg/m
3)、中污染城市(10μg/m
3≤X
1<35μg/m
3)和高污染城市(35μg/m
3≤X
1)。如何检验PM
2.5污染程度分类是否显著影响人均预期寿命?请写出详细的检验过程。
解:通过方差分析的方法进行分析。设数据结构为
| 污染浓度
|
试验数据
|
均值
|
| 低污染
|
y11 y12 … y1n1
|

|
| 中污染
|
y21 y22 … y2n2
|

|
| 高污染
|
y31 y32…y3n3
|

|
其中n
1+n
2+n
3=150。设置原假设与备择假设为
H
0:μ
1=μ
2=μ
3,H
1:μ
1,μ
2,μ
3不全相等。
计算检验统计量

若F≥F
α(2,147),拒绝原假设,认为PM
2.5污染程度分类显著影响人均预期寿命。
若F<F
α(2,147),不拒绝原假设,认为PM
2.5污染程度分类对人均预期寿命无显著影响。
5. 假设除了PM
2.5年平均浓度和人均预期寿命的数据外,你还获得了关于各城市人均GDP(X
2,单位:万元/人)和居民人均受教育程度(X
3,单位:年)。请写出一个PM
2.5年平均浓度对人均预期寿命影响的线性模型,要求考虑X
2和X
3之后,能够估计X
1每增加1个百分点导致Y变化的百分比。
解:估计X
1每增加1个百分点导致Y变化的百分比,表达了X
1的相对变化对Y的相对变化的影响。因此线性模型为

6. 基于第2小题中的模型,如何检验PM
2.5年平均浓度是否显著影响人均预期寿命。请写出详细的检验过程,列出检验使用的统计量以及自由度。
解:建立原假设与备择假设为
H
0:β
1=0,H
1:β
1≠0,
构造检验统计量

若t>t
α/2(146),则拒绝原假设,认为影响显著;若|t|<t
α/2(146),则不拒绝原假设,认为影响不显著。

 则对固定的x,
则对固定的x, 的方差为______。
的方差为______。 为σ2的无偏估计,则c等于______。
为σ2的无偏估计,则c等于______。





 的方差为
的方差为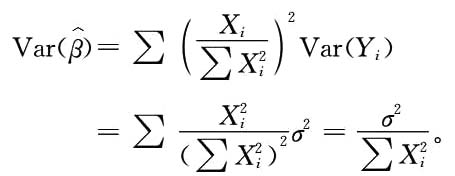


 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题