1. 给定一个二叉树根结点,复制该树,返回新建树的根结点。
用给定的二叉树的根结点root来构造新的二叉树的方法为:首先创建新的结点dupTree,然后根据root结点来构造dupTree结点(dupTree.data=root.data),最后分别用root的左右子树来构造dupTree的左右子树。根据这个思路可以实现二叉树的复制,使用递归方式实现的代码如下:
class BiTNode:
def __init__(self):
self.data=None
self.lchild=None
self.rchild=None
def createDupTree(root):
if root==None:
return None
#二叉树根结点
dupTree=BiTNode()
dupTree.data=root.data
#复制左予树
dupTree.lchild=createDupTree(root.lchild)
#复制右予树
dupTree.rchild=createDupTree(root.rchild)
return dupTree
def printTreeMidOrder(root):
if root==None:
return
#遍历root结点的左予树
if root.lchild!=None:
printTree MidOrder(root.lchild)
#遍历root结点
print root.data,
#遍历root结点的右子树
if root.rchild!=None:
printTreeMidOrder(root.rchild)
if __name__=="__main__":
root1=constructTree()
root2=createDupTree(root1)
print "原始二叉树中序遍历:",
printTreeMidOrder (root1)
print '\n'
print"新的二叉树中序遍历:",
printTreeMidOrder(root2)
程序的运行结果为:
原始二叉树中序遍历:-1 3 9 6 -7
新的二叉树中序遍历:-1 3 9 6 -7
算法性能分析:
这种方法对给定的二叉树进行了一次遍历,因此,时间复杂度为O(N),此外,这种方法需要申请N个额外的存储空间来存储新的二叉树。
[考点] 如何复制二叉树
2. 从树的根结点开始往下访问一直到叶子结点经过的所有结点形成一条路径。找出所有的这些路径,使其满足这条路径上所有结点数据的和等于给定的整数。例如:给定如下二叉树与整数8,满足条件的路径为6->3->-1(6+3-1=8)。

可以通过对二叉树的遍历找出所有的路径,然后判断各条路径上所有结点的值的和是否与给定的整数相等,如果相等,则打印出这条路径。具体实现方法可以通过对二叉树进行先序遍历来实现,实现思路为:对二叉树进行先序遍历,把遍历的路径记录下来,当遍历到叶子结点时,判断当前的路径上所有结点数据的和是否等于给定的整数,如果相等则输出路径信息,示例代码如下:
class BiTNode:
def __init__(self):
self.data=None
self.lchild=None
self.rchild=None
"""
方法功能: 打印出满足所有结点数据的和等于num的所有路径
参数: root:二叉树根结点; num:给定的整数; sum:当前路径上所有结点的和
用来存储从根结点到当前遍历到结点的路径
"""
def FindRoad(root,num,sums,v):
#记录当前遍历的root结点
sums+=root.data
v.append(root.data)
#当前结点是叶子结点且遍历的路径上所有结点的和等于num
if root.lchild==None and root.rchild==None and sums==num:
i=0
while i<len(v):
print v[i],
i+=1
print '\n'
#遍历root的左子树
if root.lchild!=None:
FindRoad(root.lchild,num,sums,v)
#遍历root的右予树
if root.rchild!=None:
FindRoad(root.rchild,num,sums,v)
#清除遍历的路径
sums-=v[-1]
v.remove(v[-1])
def constructTree():
root=BiTNode()
node1=BiTNode()
node2=BiTNode()
node3=BiTNode()
node4=BiTNode()
root.data=6
node1.data=3
node2.data=-7
node3.data=-1
node4.data=9
root.lchild=node1
root.rchild=node2
nodel.lchild=node3
nodel.rchild=node4
node2.lchild=node2.rchild=node3.lchild=node3.rchild=node4.lchild=node4.rchild=None
return root
if __name__=="__main__":
root=constructTree()
s=[]
print "满足路径结点和等于8的路径为:",
FindRoad (root,8,0,s)
程序的运行结果为:
满足路径结点和等于8的路径为:6 3 -1
算法性能分析:
这种方法与二叉树的先序遍历有着相同的时间复杂度O(N),此外,这种方法用一个数组存放遍历路径上结点的值,在最坏的情况下时间复杂度为O(N)(所有结点只有左子树,或所有结点只有右子树),因此,空间复杂度为O(N)。
[考点] 如何在二叉树中找出与输入整数相等的所有路径
3. 二叉树的镜像就是二叉树对称的二叉树,就是交换每一个非叶子结点的左子树指针和右子树指针,如下图所示,请写出能实现该功能的代码。注意:请勿对该树做任何假设,它不一定是平衡树,也不一定有序。
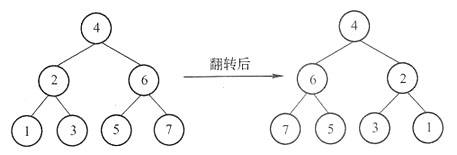
从上图可以看出,要实现二叉树的镜像反转,只需交换二叉树中所有结点的左右孩子即可。由于对所有的结点都做了同样的操作,因此,可以用递归的方法来实现,由于需要调用printTreeLayer层序打印二叉树,这种方法中使用了队列来实现,实现代码如下:
from collections import deque
class BiTNode:
def __init__(self):
self.data=None
self.lchild=None
self.rchild=None
#对二叉树进行镜像反转
def reverseTree(root):
if root==None:
return
reverseTree(root.lchild)
reverseTree(root.rchild)
tmp=root.lchild
root.lchild=root.rchild
root.rchild=tmp
def arraytotree(arr,start,end):
root=None
if end>=start:
root=BiTNode()
mid=(start+end+1)/2
#树的根结点为数组中间的元素
root.data=arr[mid]
#递归的用左半部分数组构造root的左子树
root.lchild=arraytotre e(arr,start,mid-1)
#递归的用右半部分数组构造root的右子树
root.rchild=arraytotree(arr, mid+1, end)
else:
root=None
return root
def printTreeLayer(root):
if root==None:
return
queue=deque()
#树根结点进队列
queue.append(root)
while len(queue)>0:
p=queue.popleft()
#访问当前结点
print p.data,
#如果这个结点的左孩子不为空则入队列
if p.lchild!=None:
queue.append(p.lchild)
#如果这个结点的右孩子不为空则入队列
if p.rchild!=None:
queue.append(p.rchild)
if __name__=="__main__":
arr=[1,2,3,4,5,6,7]
root=arraytotree(arr,0,len(arr)-1)
print "二叉树层序遍历结果为:",
printTreeLayer(root)
print '\n'
reverseTree(root)
print "反转后的二叉树层序遍历结果为:",
printTreeLayer(root)
程序的运行结果为:
二叉树层序遍历结果为:4 2 6 1 3 5 7
反转后的二叉树层序遍历结果为:4 6 2 7 5 3 1
算法性能分析:
由于对给定的二叉树进行了一次遍历,因此,时间复杂度为O(N)。
[考点] 如何对二叉树进行镜像反转
4. 对于一棵二叉排序树,令f=(最大值+最小值)/2,设计一个算法,找出距离f值最近、大于f值的结点。例如,下图所给定的二叉排序树中,最大值为7,最小值为1,因此,f=(1+7)/2=4,那么在这棵二叉树中,距离结点4最近并且大于4的结点为5。

首先需要找出二叉排序树中的最大值与最小值。由于二叉排序树的特点是:对于任意一个结点,它的左子树上所有结点的值都小于这个结点的值,它的右子树上所有结点的值都大于这个结点的值。因此,在二叉排序树中,最小值一定是最左下的结点,最大值一定是最右下的结点。根据最大值与最小值很容易就可以求出f的值。接下来对二叉树进行中序遍历。如果当前结点的值小于f,那么在这个结点的右子树中接着遍历,否则遍历这个结点的左子树。实现代码如下:
class BiTNode:
def __init__(self):
self.data=None
self.lchild=None
self.rchild=None
"""
方法功能: 查找值最小的结点
输入参数: root:根结点
返回值: 值最小的结点
"""
def getMinNode(root):
if root==None:
return root
while root.lchild!=None:
root=root.lchild
return root
"""
方法功能: 查找值最大的结点
输入参数: root:根结点
返回值: 值最大的结点
"""
def getMaxNode(root):
if root==None:
return root
while root.rchild!=None:
root=root.rchild
return root
def getNode(root):
maxNode=getMaxNode(root)
minNode=getMinNode(root)
mid=(maxNode.data+minNode.data)/2
result=None
while root!=None:
#当前结点的值不大于f, 则在右子树上找
if root.data<=mid:
root=root.rchild
#否则在左子树上找
else:
result=root
root=root.lchild
return result
if __name__=="__main__":
arr=[1,2,3,4,5,6,7]
root=arraytotree(arr,0,len(arr)-1)
print getNode(root).data
程序的运行结果为:
5
算法性能分析:
这种方法在查找最大结点与最小结点时的时间复杂度为O(h),h为二叉树的高度,对于有N个结点的二叉排序树,最大的高度为O(N),最小的高度为O(log2N)。同理,在查找满足条件的结点的时候,时间复杂度也是O(h)。综上所述,这种方法的时间复杂度在最好的情况下是O(logN),最坏的情况下为O(N)。
[考点] 如何在二叉排序树中找出第一个大于中间值的结点
5. 给定一棵二叉树,求各个路径的最大和,路径可以以任意结点作为起点和终点。比如给定以下二叉树:
最大和的路径为结点5→2→3,这条路径的和为10,因此返回10。
本题可以通过对二叉树进行后序遍历来解决,具体思路如下:
对于当前遍历到的结点root,假设已经求出在遍历root结点前最大的路径和为max:
(1)求出以root.left为起始结点,叶子结点为终结点的最大路径和为maxLeft;
(2)同理求出以root.right为起始结点,叶子结点为终结点的最大路径和maxRight。
包含root结点的最长路径可能包含如下三种情况:
(1)leftMax=root.val+maxLeft(左子树最大路径和可能为负)。
(2)rightMax=root.val+maxRight(右子树最大路径和可能为负)。
(3)allMax=root.val+maxLeft+maxRight(左右子树的最大路径和都不为负)。
因此,包含root结点的最大路径和为tmpMax=max(leftMax,rightMax,allMax)。
在求出包含root结点的最大路径后,如果tmpMax>max,那么更新最大路径和为tmpMax。
实现代码如下:
class TreeNode:
def __init__(self,val):
self.val=val
self.left=None
self.right=None
class IntRef:
def __init__(self):
self.val=None
#求a,b,c的最大值
def Max(a,b,c):
maxs=a if a>b else b
maxs=maxs if maxs>c else C
return maxs
#寻找最长路径
def findMaxPathRecursive(root,maxs):
if None==root:
return 0
else:
#求左子树以root.left为起始结点的最大路径和
sumLeft=findMaxPathRecursive(root.left,maxs)
#求右子树以root.right为起始结点的最大路径和
sumRight=findMaxPathRecursive(root.right,maxs)
#求以root为起始结点, 叶子结点为结束结点的最大路径和
allMax=root.val+sumLeft+sumRight
leftMax=root.val+sumLeft
rightMax=root.val+sumRight
tmpMax=Max(allMax, leftMax, rightMax)
if tmpMax>maxs.val:
maxs.val=tmpMax
subMax=sumLeft if sumLeft>sumRight else sumRight
#返回以root为起始结点, 叶子结点为结束结点的最大路径和
return root.val+subMax
def findMaxPath(root):
maxs=IntRef()
maxs.val=-2**31
findMaxPathRecursive(root,maxs)
return maxs.val
if __name__=="__main__":
root=TreeNode(2)
left=TreeNode(3)
right=TreeNode(5)
root.left=left
root.right=right
print findMaxPath(root)
程序的运行结果为
10
算法性能分析:
二叉树后序遍历的时间复杂度为O(N),因此,这种方法的时间复杂度也为O(N)。
[考点] 如何在二叉树中找出路径最大的和
6. 反向DNS查找指的是使用Internet IP地址查找域名。例如,如果你在浏览器中输入74.125.200.106,它会自动重定向到google.com。
如何实现反向DNS查找缓存?
要想实现反向DNS查找缓存,主要需要完成如下功能:
(1)将IP地址添加到缓存中的URL映射。
(2)根据给定IP地址查找对应的URL。
对于本题,常见的一种解决方案是使用字典法(使用字典来存储IP地址与URL之间的映射关系),由于这种方法相对比较简单,这里就不做详细的介绍了。下面重点介绍另外一种方法:Trie树。这种方法的主要优点如下:
(1)使用Trie树,在最坏的情况下的时间复杂度为O(1),而哈希方法在平均情况下的时间复杂度为O(1);
(2)Trie树可以实现前缀搜索(对于有相同前缀的IP地址,可以寻找所有的URL)。
当然,由于树这种数据结构本身的特性,所以使用树结构的一个最大的缺点就是需要耗费更多的内存,但是对于本题而言,这却不是一个问题,因为Internet IP地址只包含有11个字母(0到9和.)。所以,本题实现的主要思路为:在Trie树中存储IP地址,而在最后一个结点中存储对应的域名。实现代码如下:
# Trie树的结点
class TrieNode:
def __init__(self):
CHAR_COUNT=11
self.isLeaf=False
self.url=None
self.child=[None]*CHAR_COUNT #TrieNode[CHAR_COUNT]# CHAR_COUNT
i=0
while i<CHAR_COUNT:
self.child[i]=None
i+=1
def getIndexFromChar(c):
return 10 if c=='.' else (ord(c)-ord('0'))
def getCharFromIndex(i):
return '.'if i==10 else ('0'+str(i))
class DNSCache:
def __init__(self):
self.CHAR_COUNT=11 #IP地址最多有11个不同的字符
self.root=TrieNode()#IP地址最大的长度
def insert(self,ip,url):
#IP地址的长度
lens=len(ip)
pCrawl=self.root
level=0
while level<lens:
#根据当前遍历到的IP中的字符, 找出子结点的索引
index=getIndexFromChar(ip[level])
#如果子结点不存在 ,则创建一个
if pCrawl.child[index]==None:
pCrawl.child[index]=TrieNode()
#移动到子结点 #/
pCrawl=pCrawl.child[index]
#在叶子结点中存储IP对应的URL
pCrawl.isLeaf=True
pCrawl.url=url
level+=1
#通过IP地址找到对应的URL
def searchDNSCache(self,ip):
pCrawl=selfroot
lens=len(ip)
#遍历IP地址中所有的字符
level=0
while level<lens:
index=getIndexFromChar(ip[level])
if pCrawl.child[index]=None:
return None
pCrawl=pCrawl.child[index]
level+=1
#返回找到的URL
if pCrawl!=None and pCrawl.isLeaf:
return pCrawl.url
return None
if __name__=="__main__":
ipAdds=["10.57.11.127", "121.57.61.129","66.125.100.103"]
url=["www.samsung.com", "www.samsung.net", "www.google.in"]
n=len(ipAdds)
cache=DNSCache()
for i in range(n):
cache.insert(ipAdds[i],url[i])
i+=1
ip="121.57.61.129"
res_url=cache.searchDNSCache(ip)
if res_url!=None:
print "找到了IP对应的URL: \n"+ip+"--->"+res_url
else:
print "没有找到对应的URL\n"
程序的运行结果为:
找到了IP对应的URL:
121.57.61.129-->www.samsung.net
显然,由于上述算法中涉及的IP地址只包含特定的11个字符(数字和.),所以,该算法也有一些异常情况不能处理,例如不能处理用户输入的不合理的IP地址的情况,有兴趣的读者可以继续朝着这个思路完善后面的算法。
[考点] 如何实现反向DNS查找缓存




 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题