论述题1. 给定两个字符串A和B,判断字符串A中是否包含由字符串B中字符重新排列成的新字符串。例如:A=abcfde,B=dcf,结果应该返回true。因为dcf的排列cfd,是A的子串。
假设A字符串的长度为m,B字符串的长度为n。首先,如果B的长度大于A了,则肯定返回的是false。所以,本文下面的讨论都是m>=n的情况。
首先,可以计算出B的所有排列字符串,然后逐个去A中匹配。B的所有排列字符串有n!个,每一个匹配,效率太低。
那么如何改进呢?是否可以减少匹配的次数呢?可以首先对B进行排序,采用快排,时间复杂度O(nlog2n),得到D。然后在A中,从头开始,对长度为n的子串进行排序,然后判断与C与D是否相同。在A中,一共有m-n+1个长度为n的子串,每一个子串进行排序,时间复杂度为O(nlog2n),总的时间复杂度为O((m-n+1)nlog2n)即O(mnlog2n)。但其实,在A中,只有第一个C的排序的时间复杂度是O(nlog2n),其他的子串都是去掉第一个字符,然后插入下一个字符,因此排序时间复杂度为O(n),这样整体的时间复杂度为O(mn)。
继续思考,还可以利用字典查找时间复杂度为O(l)的特性,来使用字段来做对照统计即可。这样,不论字符的总类有多少,时间复杂度总是O(2n+m)。
实现代码如下:
class Test
{
static bool Contin(string str1, string str2)
{
if(str1.Length<str2.Length)
{
return false;
}
if(str2.Length==0)
{
return true;
}
//字典A
Dictionary<char, int> aMap=new Dictionary<char, int>();
//字典B
Dictionary<char, int>bMap=new Dictionary<char, int>();
//初始化字典A数据
foreach (var item in str1)
{
if(aMap.ContainsKey(item))
{
aMap[item]=aMap[item]+1;
}
else
{
aMap[item]=1;
}
}
//初始化字典B数据
foreach (var item in str2)
{
if(bMap.ContainsKey(item))
{
bMap[item]=bMap[item]+1;
}
else
{
bMap[item]=1;
}
}
//判断字典B中的Key是否完全出现在A中
foreach(var item in bMap)
{
if(aMap.ContainsKey(item.Key))
{
return aMap[item.Key]>=item.Value;
}
else
{
return false;
}
}
return true;
}
public static void Main(String[] args)
{
Console.WriteLine(Contin("abcfde","dcf"));
Console.Read();
}
}
程序的运行结果为:
True
算法性能分析:
时间复杂度为O(n),空间复杂度和给定的字符集合有关系,在本题可以看作为固定的空间大小即为O(l)。
[考点] 如何判断字符串A中是否包含由字符串B中字符重新排列成的新字符串
2. 从一个长字符串中查找包含给定字符集合的最短子串。例如,长串为“aaaaaaaaaacbebbbbbdddddddcccccc”,字符集为{abcd},那么最短子串是“acbebbbbbd”。如果将条件改为“包含且只包含给定字符集合”,那么算法和实现又将如何改动?
这是一个有趣的问题,这个有趣的问题有多种方法来解决,这个题是有些难度的,它相当于两个问题,后面的问题是第一个问题的升级,只要解决了“包含且只包含给定字符集合”的问题,第一个问题自然而然地解决,
为了阐述解决思路,这里使用一个简单例子:S=“acbbaca”,T=“aba”。这个思路主要是在遍历S时使用两个指针begin和end(窗口开始和结束位置)和两个数组(needToFind和hasFound)。needToFind存储T中不同字符的总数,hasFound存储到目前为止遇到过的不同字符的总数。同时也使用一个count变量来存储到目前为止遇到过的T中字符总数(当hasFound[x]超过needToFind[x]时不用计数)。当count等于T的长度时,就找到了一个有效的窗口。
每次向前移动end指针(指向一个元素x)时把hasFound[x]的值加1(需要判断x是否已经存在,如果存在加1,不存在就把x放进字典)如果hasFound[x]是小于或等于needToFind[x]时count加一。为什么呢?在满足约束的条件(即count等于T的大小)下,尽可能的向右移动begin指针。
如何检查是甭满足约束条件昵?假设begin指向一个元素x,可以检查hasFound[x]是否大于needToFind[x]。如果是,那么可以使hasFound[x]减一,在不破坏约束条件的前提下向前移动begin指针。如果不是,那么立即停止向前移动begin指针,以防破坏约束条件。
最后,检查最小窗口长度是否小于当前的最小窗口长度。如果不是,那么更新最小窗口长度。
本质上,该算法找到满足约束的第一个窗口后,仍然继续保持约束条件。
实现代码如下:
void MinWindow(string s, string t)
{
int slen=s.Length;
int tlen=t.Length;
//开始位置
int startWin=0;
//结束为止
int endWin=0;
if (slen<=0||tlen<=0)
{
return;
}
//存储T中不同字符的总数2的8次方
int[] needFind=new int[256];
for(int i=0;i<tlen; ++i)
{
++needFind[t[i]];
}
//存储到目前为止遇到过的不同字符的总数
int[] hasFound=newint[256];
//存储到目前为止遇到过的T中字符总数
int count=0;
int minWin=int.MaxValue;
int endEle;
for(int start=0,end=0;end<slen; ++end)
{
endEle=s[end];
//剪枝无用字符(T中字符为有用字符)
if(needFind[endEle]==0)
{
continue;
}
++hasFound[endEle];
if(hasFound[endEle]<=needFind[endEle])
{
++count;
}
//找到一个有效窗口
if(count==tlen)
{
int begEle=s[start];
//满足: 字符为无用字符, 当begEle元素找多了时start指针才向右移动
while (needFind[begEle]==0||hasFound[begEle]>needFind[begEle])
{
if(hasFound[begEle]>needFind[begEle])
{
--hasFound[begEle];
}
++start;
begEle=s[start];
}
//更新最小窗口
int curWin=end-start+1;
if(curWin<minWin)
{
minWin=curWin;
startWin=start;
endWin=end;
}
}
}
if(count==tlen)
{
Console.WriteLine(s.Substring(startWin, endWin-startWin+1));
}
else
{
Console.WriteLine("未找到");
}
}
算法性能分析:
时间复杂度为O(n2),空间复杂度为O(l)。
[考点] 如何进行子串查找
3. 请实现一个方法,将一个字符数组(最后一位是‘\0’)中的空格替换成“%20”。例如,当字符数组为“We Are Happy”,则经过替换之后的字符串为“We%20Are%20Happy”。
将长度为1的空格替换为长度为3的“%20”,字符数组的长度会变长。如果允许开辟一个新的数组来存放替换空格后的字符数组,那么这道题目就非常简单。设置两个指针分别指向新旧字符串首元素,遍历原字符串,如果碰到空格,那么就在新字符数组上填入“%20”,否则就复制原字符数组上的内容。但是如果面试官要求在原先的字符数组上操作,并且保证原字符数组有足够长的空间来存放替换后的字符数组,因此,需要思考其他的方法。
如果从前往后替换,那么保存在空格后面的字符串肯定会被覆盖,因此,可以考虑从后往前进行替换。首先遍历原字符串数组,找出字符串的长度以及其中的空格数量,根据原字符数组的长度和空格的数量就可以求出最后新字符数组的长度。设置两个指针point1和point2分别指向原字符数组和新字符数组的末尾位置。如果point1指向内容不为空格,那么将内容赋值给point2指向的位置,如果point1指向为空格,那么从point2开始赋值“02%”直到point1==point2时表明字符数组中的所有空格都已经替换完毕。
实现代码如下:
void replaceSpace(char[] str)
{
//空格的数量
int blankNumber=0;
//记录原字符串的有效长度
int oldstringLen;
//原字符串的长度
int length=str.Length;
//首先遍历原字符数组, 找出字符数组的长度以及其中的空格数量
for(oldstringLen=0; str[oldstringLen]!='\0';oldstringLen++)
{
if(str[oldstringLen]==")
blankNumber++;
}
//根据原字符数组的长度和空格的数量可以求出最后新字符数组的长度
int newstringLen=oldstringLen+blankNumber*2;//新字符串的长度
if(newstringLen>length)
{
return;
}
str[newstringLen]='\0';//此行很重要,因为原字符数组最后一个字符为'\0'
//设置两个指针point1和point2分别指向原字符数组和新字符数组的末尾位置
int point1=oldstringLen-1,point2=newstringLen-1;//因为'\0'已经手工加到最后新串的最后一个字符,所以减1
while (point1>=0&&point2>point1)
{//两指针相同时, 跳出循环
if(str[point1]==")
{ //如果point1指向为空格, 那么从point2开始赋值"02%"
str[point2--]='0';
str[point2--]='2';
str[point2--]='%';
}
else //如果point1指向内容不为空格, 那么将内容赋值给point2指向的位置
{
str[point2--]=str[point1];
}
point1--;//不管是if还是else都要把point1前移, 为了便于下一次的执行
}
算法性能分析:
时间复杂度为O(n),空间复杂度为O(l)。
[考点] 如何实现字符串的替换
4. 实现一个支持通配符匹配的算法(只支持?和*)。
其中,“?”可以匹配任何一个字符,“*”可以匹配任意序列的字符串(包括空串)。假设这个函数名字为isMatch,那么
isMatch("aa","a")→false
isMatch("aa","aa")→true
isMatch("aaa","aa")→false
isMatch("aa","/")→true
isMatch("aa","a*")→true
isMatch("ab","?*")→true
isMatch("aab","c*a*b")→false
本题中,由于只需要考虑“?”,“*”两个通配符。
对于'?'的处理,只要在匹配的时候将代码由:if(str1[i]==str2[j])改为if(str1[i]==str2[j]||str2[j]=='?')即可。
对于'*'的处理,可以将str2根据其中的'*'分为若干个片段,然后依次在str1中分别匹配这几个片段即可,而且对于这几个片段分别匹配,如果第k个片段在str1中匹配不到,那么后面也可以结束了。在进行片段匹配的时候可以采用KMP算法,来降低时间复杂度。
本题还可以利用动态规划来解决,假设字符串A[i]代表前i+1个字母组成的子字符串,B[j]代表前j+1个字母组成的子字符串,那么A[i]与B[j]是否匹配可以由A[i-1],B[j-1];A[i-1],B[j];以及A[i]B[j-1]结合当前A[i]与B[j]的字符来确定。
A[i]与B[j]匹配需进行如下判断:
定义str、strattern为即将比较的两个字符数组。
1)若(strpattern[j-1]=='?'&&str[i-1]!='\0'),或者strpattern[j-1]==str[i-1],即A[i]与B[j]的最后一个字符必须“相同”(这里相同是指必须占用一个字符),则只需判断A[i-1]和B[j-1]是否匹配;
2)若strpattern[j-1]=='*',则只需A[i]和B[j-1]匹配或者A[i-1]和B[j-1]匹配或者A[i-1]和B[j]匹配即可确定A[i]与B[j]匹配。
实现代码如下:
public bool match(char[] str, char[] strpattern)
{
int nStr=str.Length;
int nPatt=strpattern.Length;
int[][] pTable=new int[nStr+1][];
for (int k=0; k<=nStr; k++)
{
pTable[k]=new int[nPatt+1];
}
if(strpattern[0]=='*)
{
for(int i=0; i<=nPatt; ++i)
{
pTable[0][i]=1;
}
}
pTable[0][0]=1;
for(int j=1; j<=nPatt; ++j)
{
for(int i=1; i<=nStr; ++i)
{
if((strpattern[j-1]=='?' && str[i-1]!='\0')||strpattern[j-1]==str[i-1])
{
pTable[i][j]=pTable[i-1][j-1];
}
else if (strpattern[j-1]=='*')
{
if(pTable[i][j-1]==1||pTable[i-1][j]==1||pTable[i-1][j-1]==1)
pTable[i][j]=1;
}
}
}
bool ret=(pTable[nStr][nPatt]==1?true:false);
return ret;
}
算法性能分析:
算法的时间复杂度为O(n*m),空间复杂度为O(n2)。
[考点] 如何进行通配符匹配
5. 给定两个非空字符串p和s,在p中找出包含s或通过对s中字母重新排序后的字符串的子串,返回这些子串的起始下标。字符串s和p只包含小写字母,而且长度都不超过40000。例如:给定中s="cbaebabacd",p="abc",返回[0,6]。下标为0开始的子串为"cba",它可以通多s="abc"中字符重新排列生成,下标为6的类似。
本题没有太大难度,只是需要注意题目中给出的几个注意点:字符集范围,英文小写字母,返回解的顺序任意,即不需要考虑顺序。
本题可以采用滑动窗口的思想,因为不考虑顺序,所以只考虑某个字的个数。
所谓滑动窗口,即遍历的范围为固定的大小,每次移动指针的时候,窗口的大小保持不变。
实现代码如下:
public List<int> findAnagrams(string s, string p)
{
List<int>sv=new List<int>();
List<int>pv=new List<int>();
List<int>result=new List<int>();
for(int i=0;i<p.Length; i++)
{
sv[s[i]-'a']++;
pv[p[i]-'a']++;
}
//字母一共26个, 看两个数组是否相等
if(CheckValueSame(sv,pv))
{
result.Add(0);
}
for(int i=p,Length;i<s.Length; i++)
{
//从左向右, 遍历, 每次遍历一个保持窗口大小为p.size()
sv[s[i]-'a']++;
//去除窗口最左边的元素
sv[s[i-p.Length]-'a']--;
if(CheckValueSame(sv,pv))
{
result.Add(i-p.Length+1);
}
}
return result;
}
private bool CheckValueSame(List<int>s, List<int>p)
{
//字母一共26个, 看两个数组是否相等
for(int i=0;i<26;i++)
{
if(s[i]!=p[i])
{
return false;
}
}
return true;
}
算法性能分析:
时间复杂度为O(n),空间复杂度为O(n)。
[考点] 如何解决字符串包含问题
6. 给定一个字符串source和一个目标字符串target,在字符串source中找到包括所有目标字符串字母的子串。需要注意的是,在答案的子串中的字母在目标字符串中不需要具有相同的顺序。例如给出source="ADOBECODEBANC",target="ABC",满足要求的解为"BANC"。
这道题其实是要求找到包含target所有字母的最小子串,可以使用哈希表,时间复杂度为O(n),空间复杂度为O(n)。
因为大小写字母的ASCII码不大于256位,所以array['A']=3指的是'A'出现3次,array['B']=1指的是'B'出现了1次,以此类推。故而数组的长度设置为256即可存放所有的字母。
首先预处理target,用256位大小的整数数组tHash存储里面每个char出现的个数;然后给定两个指针beg和end,一个移动start,也用一个256位长的整数数组sHash记录从beg到end的这段字符串里面每个char出现的个数。如果sHash大于等于tHash,那么sHash里的每一位大于等于tHash里相应位置的值,找到当前start位置,为符合要求子串的起点,记录当前beg和end的长度,如果比已经记录的小,那么就选这个位最小窗口,记录beg和end。然后让start往前走一位。寻找下一个子串。这里使用数组是取巧,也可以使用HashMap来记录,方法类似。
实现代码如下:
public String minWindow(String source, String target)
{
int[] srcHash=new int[255];
//记录目标字符串每个字母出现次数
int i=0;
for(i=0;i<target.Length;i++)
{
srcHash[target[i]]++;
}
int start=0;
i=0;
int found=0;
int[] dectHash=new int[255];
int begin=-1;
int end=source.Length;
int minLength=source.Length;
for(start=i=0;i<source.Length; i++)
{
dectHash[source[i]]++;
if(dectHash[source[i]]<=srcHash[source[i]])
found++; //若没有到数, 添加1
if(found==target.Length)
{ //找到了能包含target的字符串, 然后去掉前面的无用字符串
while(start<i && dectHash[source[start]]>srcHash[source[start]])
{
dectHash[source[start]]--;
start++;
}
//这时候start指向该子串开头的字母, 判断该子串长度
if(i-start<minLength)
{
minLength=i-start;
begin= start;
end=i;
}
//从下一个字符串开始查找
dectHash[source[start]]--;
found--;
start++;
}
}
return begin==-1?"":source.Substring(begin, end+1);
}
算法性能分析:
时间复杂度为O(n),由于采用固定大小的空间,可以将空间复杂度为O(l)。
[考点] 如何求解最小子串覆盖问题
7. 给k个字符串,求出它们的最长公共前缀(LCP)。例如在"ABCD"、"ABEF"和"ACEF"中,LCP为"A",在"ABCDEFG"、"ABCEFG"和"ABCEFA"中,LCP为"ABC"。
这到题目最容易想到的方法就是直接两两计算前缀。
实现代码如下:
string longestCommonPrefix(List<string> strs)
{
if(strs==null||strs.Count==0)
return"";
//将集合中的index=0的字符赋值给ret
string ret=strs[0];
//遍历给定的List集合
for(int i=1;i<strs.Count;i++)
{
string cur=strs[i];
string temp=ret;
ret="";
//比较两个字符串中每个位置的字符, 直到较短的字符结束
for(int j=0; j<Math.Min(temp.Length, cur.Length); j++)
{
if(temp[j]==cur[j])
ret+=cur[j];
else
break;
}
}
return ret;
}
算法性能分析:
需要借助一个存放公共前缀的空间,空间复杂度可以看作为O(l),时间复杂度跟k和最小字符长度有关,最坏情况为O(k*n)。
[考点] 如何找出字符串的最长公共前缀
8. 给出一个字符串A,表示一个n位正整数,删除其中k位数字,使得剩余的数字仍然按照原来的顺序排列产生一个新的正整数,找到删除k个数字之后的最小正整数。要求n<=240,k<=n。
例如A="178542",k=4,返回一个字符串"12"。
在删除数字时,应从高位开始删除,例如上面的范例数字。178542要从中删除4位数字使得剩下的数字最小,那么第一个应该删除的是数字8然后删除的是7再然后就是5,最后删除的是4,最终看到结果就是13基于此想法,并总结出规律:最优解是删除出现的第一个左边>右边的数,因为删除之后高位减小。
实现代码如下:
string deleteKNumbers(string str, int k)
{
StringBuilder sb=new StringBuilder(str);
int start=0;
bool flag;
for(int i=k;i>0;--1)
{
flag=false;
for(start=0;start<str.Length-1; start++)
{
if(sb[start]>sb[start+1])//每次删除第一个比下一个数字大的数
{
sb.Remove(start,1);
flag=true;
break;
}
}
if(!flag)//如果所有数字递增, 则删除最后几个数字后直接返回
{
sb.Remove(str.Length-k, k);
break;
}
}
return sb.ToString();
}
算法性能分析:
需要借助一个存储空间,空间复杂度可以看作为O(n),时间复杂度为0(n)。
[考点] 如何找到数组删除k个数字之后的最小正整数
9. 给定一个字符串,找出最长的没有重复字符的子串的长度。例如,给定"abcabcbb",最长的没有重复字符的子串为的"abc",长度为3。给定字符串"bbbbb",最长的没有重复字符的子串为"b",长度为1。
本题难度较小,解法比较多,可以借助一个Hash表来求解。通过Hash表,并附设两个“指针”i和j;用字符的整数值当索引,值为0或1表示是否之前存在。当存在了,就执行i++,否则j++并更新hash表的值。
实现代码如下:
int LengthOfLongestSubstring(char[] str)
{
int i,j;
int maxlen=0; //要初始化, 不然产生意外结果!
int n=str.Length;
int[] arr=new int[255]; //设置Hash表, 索引为字符的值, 值为是否存在该字符!
for(i=0, j=0; j<n; j++)
{
while(arr[str[j]]==1)
{
arr[str[i]]=0;
++i;
}
arr[str[j]]=1;
maxlen=maxlen>(j-i)?maxlen:j-1+1;
}
return maxlen;
}
算法性能分析:
由于字符的范围是有限的,需要借助一个固定的存储空间,因此本方法的空间复杂度可以看作为O(l),由于需要遍历一遍数组,所以算法的时间复杂度为O(n)。
[考点] 如何查找没有重复字符的最长子串
10. 不使用库函数,计算给定数的平方根,例如:
sqrt(3)=1
sqrt(4)=2
sqrt(5)=2
sqrt(10)=3
本题需要求解一个整数的平方根,更准确地说是平方根的向下取整的整数,可以采用二分法来进行求解。需要注意的是,计算结果可能并不是待求整数的数学平方根,有可能是待求数的平方根是介于两个整数之间的数,而这种情况需要做一下判断处理,否则程序会陷入死循环中。
根据以上思路,实现代码如下:
public class Test{
public static int Sqrt(int x)
{
if(x==0)
{
return0;
}
//int的最大值为2
32次方, 平方根的最大值为46341
int left=1, right=46341;
int mid=0;
while(left<right)
{
//中间值与左右边界的和的一半是相等的, 那么现在的中间值就是上一循环中已经使用过的
//直接退出循环即可
if (mid==(left+right)/2)
{
break;
}
mid=(left+right)/2;
if(mid*mid==x)
{
return mid;
else if(mid * mid<x)
{
left=mid;
}
else
{
right=mid;
}
}
return mid;
}
public static void Main(String[] args)
{
Console.Write(Sqrt(3)+"\t");
Console.Write(Sqrt(4)+"\t");
Console.Write(Sqrt(5)+"\t");
Console.Write(Sqrt(10)+"\t");
Console.Read();
}
}
程序运行结果为:
1 2 2 3
算法性能分析: 由于本题采用了二分法,算法的时间复杂度和x的大有关,因此算法的时间复杂度可以看作为
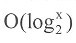
。
[考点] 如何不使用库函数求解整数x的平方根



 深色:已答题 浅色:未答题
深色:已答题 浅色:未答题